编程与调试 -- Tiny Source Code, Tiny My Life
setlocale(LC_ALL, "chs");
#include <atlbase.h>
#include <atlconv.h>
#include <atlstr.h>
USES_CONVERSION_EX;
CW2A(L"中文字符", CP_UTF8);
USES_CONVERSION 或 USES_CONVERSION_EX 在将 UNICODE 转化到 UTF-8 过程中,可能导致失败。  W2A_CP 不靠谱,Unicode 转 UTF-8 可能失败。
W2A_CP 不靠谱,Unicode 转 UTF-8 可能失败。
// warning C4715: 不是所有的控件路径都返回值
/we4715 /we4013 /we4431 /we4133 /we4716 /we4457 /we4456 /we4172 /we4700 /we4477 /we4018 /we4047
// vcruntime140_1.dll -- x64 test.exe
// x64 test.exe -- __CxxFrameHandler4 VCRUNTIME140_1
void OcrLite::Logger(const char *format, ...) {
if (!(isOutputConsole || isOutputResultTxt)) return;
char *buffer = (char *) malloc(8192);
va_list args;
va_start(args, format);
vsprintf(buffer, format, args);
va_end(args);
if (isOutputConsole) printf("%s", buffer);
if (isOutputResultTxt) fprintf(resultTxt, "%s", buffer);
free(buffer);
}
析构函数 (C++)
note 对析构函数的调用可以执行相应的清理。 若要显式调用 s 类的对象 String 的析构函数,请使用下列语句之一:
s.String::~String(); // non-virtual call
ps->String::~String(); // non-virtual call
s.~String(); // Virtual call
ps->~String(); // Virtual call
C++ 17 std::filesystem
C++ 判断文件或者目录是否存在  Filesystem library (since C++17)
Filesystem library (since C++17)
#include <filesystem>
std::string file_name = "deadman";
if (std::filesystem::exists(file_name)) {
if (std::filesystem::is_directory(file)) {
printf("%s is a directory\n", file_name.c_str());
} else if (std::filesystem::is_regular_file(file)) {
printf("%s is a file\n", file_name.c_str());
} else {
printf("%s exists\n", file_name.c_str());
}
} else {
printf("%s does not exist\n", file_name.c_str());
}
#include <sys/types.h>
#include <sys/stat.h>
std::string file_name = "deadman";
struct stat info;
if (stat(file_name.c_str(), &info) != 0) { // does not exist
printf("cannot access %s\n", file_name.c_str());
} else if (info.st_mode & S_IFDIR) { // directory
printf("%s is a directory\n", file_name.c_str());
} else {
printf("%s is no directory\n", file_name.c_str());
}
红黑树 / Set / Map
D:\Android\Sdk\ndk\21.1.6352462\sources\cxx-stl\llvm-libc++\include\__tree
note
note  C++ STL 中,C++ 中 set, multiset, map, multimap 集合模板类都是在 STL 红黑树的基础之上实现的。
C++ STL 中,C++ 中 set, multiset, map, multimap 集合模板类都是在 STL 红黑树的基础之上实现的。
Win32 上,debug 都是 12 字节,release 都是 8 字节(有个代理位,涉及一个关键的宏 _ITERATOR_DEBUG_LEVEL )。
Android 上非常标准,感觉都是 12 字节,leftptr, rightptr, size。
分别是:
auto mymap = std::map<int, int>();
_Myproxy;
_Myhead std::_Tree_node<std::pair<int const, int>, void*>*;
_Mysize unsigned int;
auto mymmap = std::multimap<int, int>();
_Myproxy;
_Myhead std::_Tree_node<std::pair<int const, int>, void*>*;
_Mysize unsigned int;
auto myset = std::set<int>();
_Myproxy;
_Myhead std::_Tree_node<int, void*>*;
_Mysize unsigned int;
auto mymset = std::multiset<int>();
_Myproxy;
_Myhead std::_Tree_node<int, void*>*;
_Mysize unsigned int;
_Left *
_Parent *
_Right *
_Color char
_Isnil char
_Myval int
结构体内存对齐问题
note 结构体内存对齐问题:
- 结构体变量的起始地址能够被其最宽的成员大小整除。
- 结构体每个成员相对于起始地址的偏移能够被其自身大小整除,如果不能则在前一个成员后面补充字节。
- 结构体总体大小能够被最宽的成员的大小整除,如不能则在后面补充字节。
struct S3 {
double d;
char c;
int i;
};
struct S4 {
char c1;
struct S3 s3;
double d;
};
int tempk = sizeof(struct S4); // 32
tempk = sizeof(struct S3); // 16
tempk = 0;
栈的生长方向和内存存放方向
Heap :堆是往高地址增长的,是用来动态分配内存的区域,malloc 就是在这里面分配的;
在这 4G 里面,其中 1G 是内核态内存,每个 Linux 进程共享这一块内存,在高地址;3G 是用户态内存,这部分内存进程间不共享,在低地址。
from
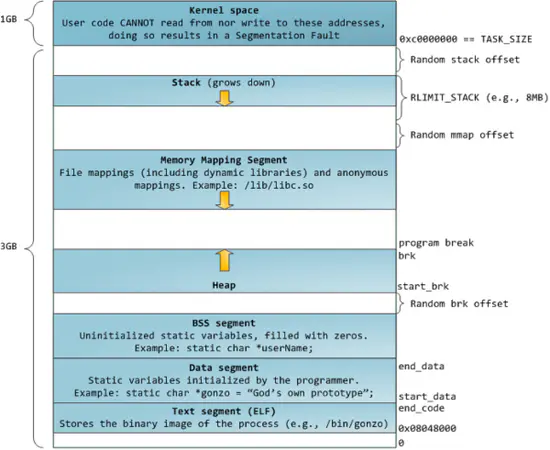
生长方向:栈的开口向下,堆的开口向上(小端模式)。 栈每压入一个内存块,即在栈的下端开辟出来,该内存块的首地址是在该内存块的最下面。 内存块里的数据生长方向,是向上的(与栈本身的生长方向是相反的), 这一点对堆来讲也适用(当然,堆的开口本来就朝上,很好理解)。 Android & Windows 是一致的。
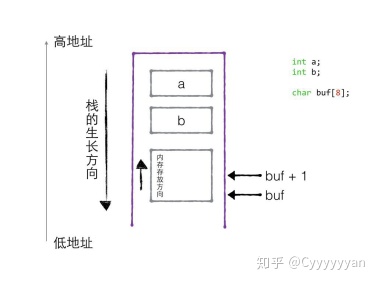
#include <iostream>
struct MyStruct {
int a = 10;
int b = 20;
int c = 30;
int d = 40;
};
// 1. 栈的生长方向
void test01() {
int a = 10;
int b = 20;
int c = 30;
int d = 40;
MyStruct st;
// a 的地址大于 b 的地址,故而生长方向向下。
printf("a = %d\n", &a); // a = 5240956
printf("b = %d\n", &b); // b = 5240944
printf("c = %d\n", &c); // c = 5240932
printf("d = %d\n", &d); // d = 5240920
printf("a = %d\n", &st.a); // a = 5240896
printf("b = %d\n", &st.b); // b = 5240900
printf("c = %d\n", &st.c); // c = 5240904
printf("d = %d\n", &st.d); // d = 5240908
}
// 2. 内存生长方向(小端模式)
void test02() {
// 高位字节 -> 地位字节
int num = 0xaabbccdd;
unsigned char* p = (unsigned char*)#
// 从首地址开始的第一个字节
printf("%x\n", *p); // dd
printf("%x\n", *(p + 1)); // cc
printf("%x\n", *(p + 2)); // bb
printf("%x\n", *(p + 3)); // aa
}
int main()
{
test01();
test02();
return 0;
}
NCNN 问题整理
ncnn 小白常见问题整理  Win10 下 QT + NCNN 实现 Android 开发的踩坑记录
Win10 下 QT + NCNN 实现 Android 开发的踩坑记录
rtti/exceptions 冲突
在 Android NDK(JNI)代码中遇到报错 error: use of typeid requires -frtti 。
原因:ncnn 的 android 预编译包的编译选项中,禁用了 rtti (同时还禁用了 exceptions ),而 OpenCV 的 android 预编译包开启了 rtti 和 exceptions (这是在 NDK 的 toolchains.cmake 中默认开启的);当两个(或多个)库的 rtti、exceptions 编译选项设定不同时,会导致冲突,需要统一。
方法:重编 ncnn,编译时开启 rtti、exceptions 。
- 在命令行(或 CMake-GUI)里,用 cmake 构建,构建时传入
-DNCNN_DISABLE_EXCEPTION=OFF -DNCNN_DISABLE_RTTI=OFF;如果先前构建过,请清理 build/CMakeCache.txt;不要在 Android Studio 里构建 ncnn 库,因为很可能你的 rtti 和 exceptions 还是弄错。
最终,通过直接暴力修改 ncnn CMakeLists.txt 文件,顺利编译出来。
为啥自己编译的 ncnn android 库特别大?
很可能是没有去掉 -g 导致的。 这个不用解决,大点就大点吧。
基于 cmake 和 ninja,自行编译 ncnn 的 android 库,编译时注意:
- 去掉
-g参数以减小库体积:打开$ANDROID_NDK/build/cmake/android.toolchain.cmake# 删除 "-g" 这行 list(APPEND ANDROID_COMPILER_FLAGS -g -DANDROID
ADD_LIBRARY SHARED not support
这行代码造成的:set_property(GLOBAL PROPERTY TARGET_SUPPORTS_SHARED_LIBS FALSE) 。
ADD_LIBRARY called with SHARED option but the target platform does not
support dynamic linking. Building a STATIC library instead.
> Task :prepareKotlinBuildScriptModel UP-TO-DATE
D:\kSource\kv\engine\src\main\cpp\CMakeLists.txt : C/C++ debug|arm64-v8a :
CMake Warning (dev) at D:\kSource\kv\engine\src\main\cpp\CMakeLists.txt:196 (add_library):
ADD_LIBRARY called with SHARED option but the target platform does not
support dynamic linking. Building a STATIC library instead. This may lead
to problems.
This warning is for project developers. Use -Wno-dev to suppress it.
BUILD SUCCESSFUL in 860ms
/* ideally we should check whether for the linker language of the target
CMAKE_${LANG}_CREATE_SHARED_LIBRARY is defined and if not default to
STATIC. But at this point we know only the name of the target, but not
yet its linker language. */
if ((type == cmStateEnums::SHARED_LIBRARY ||
type == cmStateEnums::MODULE_LIBRARY) &&
!mf.GetState()->GetGlobalPropertyAsBool("TARGET_SUPPORTS_SHARED_LIBS")) {
mf.IssueMessage(
MessageType::AUTHOR_WARNING,
cmStrCat(
"ADD_LIBRARY called with ",
(type == cmStateEnums::SHARED_LIBRARY ? "SHARED" : "MODULE"),
" option but the target platform does not support dynamic linking. ",
"Building a STATIC library instead. This may lead to problems."));
type = cmStateEnums::STATIC_LIBRARY;
}
OpenCV 相关
int cvtype = CV_8UC1; // 0
cvtype = CV_8UC2; // 8
cvtype = CV_8UC3; // 16
cvtype = CV_32FC1; // 5
cvtype = CV_32FC3; // 21
// std::vector Debug 版本第一位是:`_Myproxy` 。
#if _ITERATOR_DEBUG_LEVEL != 0
#define MatVecFirst(x) ( (cv::Mat*) ((size_t*)&(x))[1] )
#define MatVecLast(x) ( (cv::Mat*) ((size_t*)&(x))[2] )
#define MatVecEnd(x) ( (cv::Mat*) ((size_t*)&(x))[3] )
#else
#define MatVecFirst(x) ( (cv::Mat*) ((size_t*)&(x))[0] )
#define MatVecLast(x) ( (cv::Mat*) ((size_t*)&(x))[1] )
#define MatVecEnd(x) ( (cv::Mat*) ((size_t*)&(x))[2] )
#endif
#define MatVecLen(x) ((char*)MatVecLast(x) - (char*)MatVecFirst(x))
#define MatVecCount(x) ((unsigned int)(-1227133513 * (MatVecLen(x) >> 3)))
#if _ITERATOR_DEBUG_LEVEL != 0
#define UMatVecFirst(x) ( (cv::UMat*) ((size_t*)&(x))[1] )
#define UMatVecLast(x) ( (cv::UMat*) ((size_t*)&(x))[2] )
#define UMatVecEnd(x) ( (cv::UMat*) ((size_t*)&(x))[3] )
#else
#define UMatVecFirst(x) ( (cv::UMat*) ((size_t*)&(x))[0] )
#define UMatVecLast(x) ( (cv::UMat*) ((size_t*)&(x))[1] )
#define UMatVecEnd(x) ( (cv::UMat*) ((size_t*)&(x))[2] )
#endif
#define UMatVecLen(x) ((char*)UMatVecLast(x) - (char*)UMatVecFirst(x))
#define UMatVecCount(x) ((unsigned int)(-1431655765 * (UMatVecLen(x) >> 2)))
| -1227133513 » 3 | 0xb6db6db7 | 56 / cv::Mat |
| -1431655765 » 2 | 0xaaaaaaab | 12 / MyStructX? |
| -858993459 » 4 | 0xcccccccd | 80 / MyStructk80 |
| -1717986918 » 4 | 0x9999999a | 40? |
| 1431655766 » 2 | 0x55555556 | 6? |
| 858993460 » 4 | 0x33333334 | 20? |
https://gmplib.org/devel/bc_bin_uiui.c https://datatracker.ietf.org/doc/html/draft-valin-celt-codec-00
#include <iostream>
#include <assert.h>
static unsigned int zinvArray[] = {
0x00000001, /* 1 */ 0x00000001, /* 2 */
0xaaaaaaab, /* 3 */ 0x00000001, /* 4 */
0xcccccccd, /* 5 */ 0xaaaaaaab, /* 6 */
0xb6db6db7, /* 7 */ 0x00000001, /* 8 */
0x38e38e39, /* 9 */ 0xcccccccd, /* 10 */
0xba2e8ba3, /* 11 */ 0xaaaaaaab, /* 12 */
0xc4ec4ec5, /* 13 */ 0xb6db6db7, /* 14 */
0xeeeeeeef, /* 15 */ 0x00000001, /* 16 */
0xf0f0f0f1, /* 17 */ 0x38e38e39, /* 18 */
0x286bca1b, /* 19 */ 0xcccccccd, /* 20 */
0x3cf3cf3d, /* 21 */ 0xba2e8ba3, /* 22 */
0xe9bd37a7, /* 23 */ 0xaaaaaaab, /* 24 */
0xc28f5c29, /* 25 */ 0xc4ec4ec5, /* 26 */
0x684bda13, /* 27 */ 0xb6db6db7, /* 28 */
0x4f72c235, /* 29 */ 0xeeeeeeef, /* 30 */
0xbdef7bdf, /* 31 */ 0x00000001 /* 32 */
};
static unsigned char ctzArray[] =
{ 0,1,0,2,0,1,0,3,0,1,0,2,0,1,0,4,0,1,0,2,0,1,0,3,0,1,0,2,0,1,0,5 };
void check(int num, int zinv, int ctz) {
if (num <= 32) {
printf("**[%d] %x,%d / ref %x,%d \n",
num, zinv, ctz, zinvArray[num - 1], ctzArray[num - 1]);
assert(zinv == zinvArray[num - 1]);
assert(ctz == ctzArray[num - 1]);
}
for (int i = 0; i < 1000; i++) {
if (i % num != 0) continue;
auto value1 = i / num;
auto value2 = zinv * (i >> ctz);
// printf("%d,%d,%d,%d -- %d %d \n", i, num, zinv, ctz, value1, value2);
assert(value1 == value2);
}
}
/* INV_TABLE[i] holds the multiplicative inverse of (2*i+1) mod 2**32. */
static const unsigned int INV_TABLE[128] = {
0x00000001, 0xAAAAAAAB, 0xCCCCCCCD, 0xB6DB6DB7,
0x38E38E39, 0xBA2E8BA3, 0xC4EC4EC5, 0xEEEEEEEF,
0xF0F0F0F1, 0x286BCA1B, 0x3CF3CF3D, 0xE9BD37A7,
0xC28F5C29, 0x684BDA13, 0x4F72C235, 0xBDEF7BDF,
0x3E0F83E1, 0x8AF8AF8B, 0x914C1BAD, 0x96F96F97,
0xC18F9C19, 0x2FA0BE83, 0xA4FA4FA5, 0x677D46CF,
0x1A1F58D1, 0xFAFAFAFB, 0x8C13521D, 0x586FB587,
0xB823EE09, 0xA08AD8F3, 0xC10C9715, 0xBEFBEFBF,
0xC0FC0FC1, 0x07A44C6B, 0xA33F128D, 0xE327A977,
0xC7E3F1F9, 0x962FC963, 0x3F2B3885, 0x613716AF,
0x781948B1, 0x2B2E43DB, 0xFCFCFCFD, 0x6FD0EB67,
0xFA3F47E9, 0xD2FD2FD3, 0x3F4FD3F5, 0xD4E25B9F,
0x5F02A3A1, 0xBF5A814B, 0x7C32B16D, 0xD3431B57,
0xD8FD8FD9, 0x8D28AC43, 0xDA6C0965, 0xDB195E8F,
0x0FDBC091, 0x61F2A4BB, 0xDCFDCFDD, 0x46FDD947,
0x56BE69C9, 0xEB2FDEB3, 0x26E978D5, 0xEFDFBF7F,
0x0FE03F81, 0xC9484E2B, 0xE133F84D, 0xE1A8C537,
0x077975B9, 0x70586723, 0xCD29C245, 0xFAA11E6F,
0x0FE3C071, 0x08B51D9B, 0x8CE2CABD, 0xBF937F27,
0xA8FE53A9, 0x592FE593, 0x2C0685B5, 0x2EB11B5F,
0xFCD1E361, 0x451AB30B, 0x72CFE72D, 0xDB35A717,
0xFB74A399, 0xE80BFA03, 0x0D516325, 0x1BCB564F,
0xE02E4851, 0xD962AE7B, 0x10F8ED9D, 0x95AEDD07,
0xE9DC0589, 0xA18A4473, 0xEA53FA95, 0xEE936F3F,
0x90948F41, 0xEAFEAFEB, 0x3D137E0D, 0xEF46C0F7,
0x028C1979, 0x791064E3, 0xC04FEC05, 0xE115062F,
0x32385831, 0x6E68575B, 0xA10D387D, 0x6FECF2E7,
0x3FB47F69, 0xED4BFB53, 0x74FED775, 0xDB43BB1F,
0x87654321, 0x9BA144CB, 0x478BBCED, 0xBFB912D7,
0x1FDCD759, 0x14B2A7C3, 0xCB125CE5, 0x437B2E0F,
0x10FEF011, 0xD2B3183B, 0x386CAB5D, 0xEF6AC0C7,
0x0E64C149, 0x9A020A33, 0xE6B41C55, 0xFEFEFEFF
};
int main()
{
int count = sizeof(zinvArray) / sizeof(zinvArray[0]);
int count2 = sizeof(ctzArray) / sizeof(ctzArray[0]);
assert(count == count2);
for (int i = 0; i < count; i++) {
check(i + 1, zinvArray[i], ctzArray[i]);
}
int countx = sizeof(INV_TABLE) / sizeof(INV_TABLE[0]);
for (int num = 1; num <= 2000; num++) {
if (num % 2 == 0) {
int shift = 0;
int temp = num;
while (temp && (temp % 2 == 0)) {
shift++;
temp = temp >> 1;
}
int index = (temp - 1) / 2;
if (index >= countx) continue;
printf("num=%d idx=%d inv=%x shift=%d \n",
num, index, INV_TABLE[index], shift);
check(num, INV_TABLE[index], shift);
} else {
int index = (num - 1) / 2;
if (index >= countx) continue;
printf("num=%d idx=%d inv=%x shift=%d \n",
num, index, INV_TABLE[index], 0);
check(num, INV_TABLE[index], 0);
}
}
getchar();
return 0;
}
cwrs.c Math behind gcc9+ modulus optimizations
| cv::fastFree() | fastFree(step.p) | 11 |
| cv::Mat::deallocate((int)&v120); | deallocate(); | cv::Mat |
整数定数除法的代换 (constant integer division)
#include <iostream>
int checkdiv(int num, int div, bool output=false, int shdiv=1) {
bool retv = true;
for (int i = 0; i < 9100; i++) {
if (i % div) continue;
if (output && (i < 100 || i >= 9000)) {
printf("[%d]%s [0x%x/%d,%d] %d -- %d \n", //
i, retv ? "True" : "False", //
num, shdiv, div, i * num / shdiv, i / div);
}
if (i * num / shdiv != i / div) {
retv = false;
}
}
return retv;
}
int checkdiv(int num) {
for (int x = 2; x <= 200; x++) {
if (checkdiv(num, x)) {
return x;
}
}
return 0;
}
void printdiv(int num, int div) {
printf("printdiv %d %d \n", num, div);
}
int main()
{
int ksize = klistsize;
// 1431655766?
int div = 0;
if (div = checkdiv(1431655766)) {
printdiv(1431655766, div);
}
checkdiv(1431655766, 3, true, 2);
for (int i = 0; i < ksize; i++) {
if (div = checkdiv(klist[i])) {
printdiv(klist[i], div);
}
}
getchar();
return 0;
}
#define CASE_RETURN(x) case x: return L ## #x
inline std::string GetKernelCode(const std::string & filename)
{
std::stringstream buffer;
buffer << std::ifstream(filename.c_str()).rdbuf();
return buffer.str();
}
if (!PathFileExists(fpath)) {
CreateDirectory(fpath, NULL);
}
wchar_t fpath[MAX_PATH + 1] = { 0 };
DWORD res = GetTempPath(MAX_PATH, fpath);
if (res <= 0 || res >= MAX_PATH) {
return gpuip::GPUIP_CODE::CODE_ERROR;
}
// 加载 dll 不要弹框报错。
auto modex = SEM_FAILCRITICALERRORS | //
SEM_NOALIGNMENTFAULTEXCEPT | //
SEM_NOGPFAULTERRORBOX | //
SEM_NOOPENFILEERRORBOX;
auto modebak = ::SetErrorMode(modex);
HINSTANCE hDLL = LoadLibrary(current.c_str());
auto modey = ::SetErrorMode(modebak);
assert(modey == modex);
/**
4294967293 fffffffd -- -3 fffffffd
4294967294 fffffffe -- -2 fffffffe
4294967295 ffffffff -- -1 ffffffff
0 0 -- 0 0
1 1 -- 1 1
2 2 -- 2 2
3 3 -- 3 3*/
for (int i = -3; i <= 3; i++) {
unsigned int ui = (unsigned int) i;
printf("%u %x -- %d %x \n", i, i, ui, ui);
}
// 64 位版本:
int a = sizeof(int); // 4
a = sizeof(long); // 4
a = sizeof(long long); // 8
a = sizeof(__int64); // 8
a = sizeof(void*); // 8
a = 0;
cv::Mat 内存结构
出现 .dims = (int) 的都不对。
| x | cv::Mat | cv::UMat | cv::_InputArray |
|---|---|---|---|
| 0 | int flags; | int flags; | int flags; |
| 1 | int dims; | int dims; | void* obj; |
| 2 | int rows; | int rows; | Size sz.width; |
| 3 | int cols; | int cols; | Size sz.height; |
| 4 | uchar* data; | MatAllocator* allocator; | |
| 5 | const uchar* datastart; | UMatUsageFlags usageFlags; | |
| 6 | const uchar* dataend; | UMatData* u; | |
| 7 | const uchar* datalimit; | size_t offset; | |
| 8 | MatAllocator* allocator; | MatSize size; | |
| 9 | UMatData* u; | MatStep step.p; | |
| 10 | MatSize size; | MatStep step.buf[0]; | |
| 11 | MatStep step.p; size_t* |
MatStep step.buf[1]; | |
| 12 | MatStep step.buf[0]; size_t |
||
| 13 | MatStep step.buf[1]; size_t |
| x | 老版本 ncnn::Mat(40 字节) 应该以这个为准 |
最新版本 ncnn::Mat(44 字节) |
|---|---|---|
| 0 | void* data; | void* data; |
| 1 | int* refcount; | int* refcount; |
| 2 | size_t elemsize; | size_t elemsize |
| 3 | int elempack; | int elempack; |
| 4 | Allocator* allocator; | Allocator* allocator; |
| 5 | int dims; | int dims; |
| 6 | int w; | int w; |
| 7 | int h; | int h; |
| 8 | int c; | int d; |
| 9 | size_t cstep; | int c; |
| 10 | size_t cstep; |
| x | cv::MatExpr | cv::Moments |
|---|---|---|
| 0 | const MatOp* op; | |
| 1 | int flags; | |
| 2-15 | Mat a; | |
| 16-29 | Mat b; | |
| 30-43 | Mat c; | |
| 44-45 | double alpha; | |
| 46-47 | double beta; | |
| 48-55 | Scalar s; |
- double m00, m10, m01, m20, m11, m02, m30, m21, m12, m03;
- double mu20, mu11, mu02, mu30, mu21, mu12, mu03;
- double nu20, nu11, nu02, nu30, nu21, nu12, nu03;
cv::cvtColor(src, tempmat, cv::COLOR_RGBA2RGB); [ROOT]\opencv\opencv-3.4.2_vs2019_win64\installR\include\opencv2\imgproc.hpp
enum ColorConversionCodes {
COLOR_BGR2BGRA = 0, //!< add alpha channel to RGB or BGR image
COLOR_RGB2RGBA = COLOR_BGR2BGRA,
COLOR_BGRA2BGR = 1, //!< remove alpha channel from RGB or BGR image
COLOR_RGBA2RGB = COLOR_BGRA2BGR,
COLOR_BGR2RGBA = 2, //!< convert between RGB and BGR color spaces (with or without alpha channel)
COLOR_RGB2BGRA = COLOR_BGR2RGBA,
COLOR_RGBA2BGR = 3,
COLOR_BGRA2RGB = COLOR_RGBA2BGR,
COLOR_BGR2RGB = 4,
COLOR_RGB2BGR = COLOR_BGR2RGB,
COLOR_BGRA2RGBA = 5,
COLOR_RGBA2BGRA = COLOR_BGRA2RGBA,
COLOR_BGR2GRAY = 6, //!< convert between RGB/BGR and grayscale, @ref color_convert_rgb_gray "color conversions"
COLOR_RGB2GRAY = 7,
COLOR_BGRA2GRAY = 10,
COLOR_RGBA2GRAY = 11,
COLOR_BGR2HSV = 40, //!< convert RGB/BGR to HSV (hue saturation value), @ref color_convert_rgb_hsv "color conversions"
COLOR_RGB2HSV = 41,
};
[ROOT]\opencv\opencv-3.4.2\modules\core\include\opencv2\core\mat.inl.hpp
inline
Mat::~Mat()
{
release();
if ( step.p != step.buf )
fastFree(step.p);
}
inline
void Mat::release()
{
if ( u && CV_XADD(&u->refcount, -1) == 1 )
deallocate();
u = NULL;
datastart = dataend = datalimit = data = 0;
for (int i = 0; i < dims; i++)
size.p[i] = 0;
}
// 生成汇编
if ( v83.u ) {
v32 = &v83.u->refcount;
v33 = GetAndSub((unsigned int *)v32);
if ( v33 == 1 )
CvMatDeallocate(&v83);
}
v83.u = 0;
v34 = (int *)v83.dims;
memset(&v83.data, 0, 16); // datastart = dataend = datalimit = data = 0;
if ( v83.dims >= 1 ) {
v34 = v83.size.p;
v35 = 0;
do {
v34[v35++] = 0;
v31 = v83.dims;
}
while ( v35 < v83.dims );
}
if ( v83.step.p != v83.step.buf )
CvFastFree((mycv *)v83.step.p, v34);
inline
Mat& Mat::operator = (Mat&& m)
{
if (this == &m)
return *this;
release();
flags = m.flags; dims = m.dims; rows = m.rows; cols = m.cols; data = m.data;
datastart = m.datastart; dataend = m.dataend; datalimit = m.datalimit; allocator = m.allocator;
u = m.u;
if (step.p != step.buf) { // release self step/size
fastFree(step.p);
step.p = step.buf;
size.p = &rows;
}
if (m.dims <= 2) { // move new step/size info
step[0] = m.step[0];
step[1] = m.step[1];
} else {
CV_DbgAssert(m.step.p != m.step.buf);
step.p = m.step.p;
size.p = m.size.p;
m.step.p = m.step.buf;
m.size.p = &m.rows;
}
m.flags = MAGIC_VAL; m.dims = m.rows = m.cols = 0;
m.data = NULL; m.datastart = NULL; m.dataend = NULL; m.datalimit = NULL;
m.allocator = NULL;
m.u = NULL;
return *this;
}
inline
Mat& Mat::operator = (const Mat& m)
{
if ( this != &m ) {
if ( m.u )
CV_XADD(&m.u->refcount, 1);
release();
flags = m.flags;
if ( dims <= 2 && m.dims <= 2 ) {
dims = m.dims;
rows = m.rows;
cols = m.cols;
step[0] = m.step[0];
step[1] = m.step[1];
} else
copySize(m);
data = m.data;
datastart = m.datastart;
dataend = m.dataend;
datalimit = m.datalimit;
allocator = m.allocator;
u = m.u;
}
return *this;
}
inline
Mat::Mat(const Mat& m)
: flags(m.flags), dims(m.dims), rows(m.rows), cols(m.cols), data(m.data),
datastart(m.datastart), dataend(m.dataend), datalimit(m.datalimit), allocator(m.allocator),
u(m.u), size(&rows), step(0)
{
if ( u )
CV_XADD(&u->refcount, 1);
if ( m.dims <= 2 ) {
step[0] = m.step[0]; step[1] = m.step[1];
} else {
dims = 0;
copySize(m);
}
}
inline Mat& Mat::operator=(const Mat& m)
{
if (this == &m)
return *this;
if (m.refcount)
NCNN_XADD(m.refcount, 1);
release();
data = m.data;
refcount = m.refcount;
elemsize = m.elemsize;
elempack = m.elempack;
allocator = m.allocator;
dims = m.dims;
w = m.w;
h = m.h;
c = m.c;
cstep = m.cstep;
return *this;
}
inline void Mat::release()
{
if (refcount && NCNN_XADD(refcount, -1) == 1) {
if (allocator)
allocator->fastFree(data);
else
fastFree(data);
}
data = 0;
elemsize = 0;
elempack = 0;
dims = 0;
w = 0;
h = 0;
c = 0;
cstep = 0;
refcount = 0;
}
inline
Mat Mat::clone() const
{
Mat m;
copyTo(m);
return m;
}
Mat - 成员变量的 flags 的含义
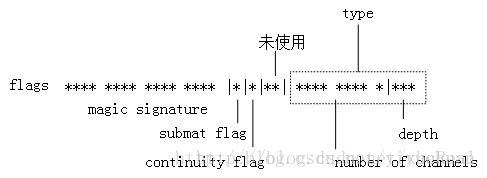
| 33619968 | 0x2010000 | (cv::ACCESS_WRITE+cv::MAT) |
| 16842752 | 0x1010000 | (cv::ACCESS_READ+cv::MAT) |
| 33882112 | 0x2050000 | (cv::ACCESS_WRITE+cv::STD_VECTOR_MAT) std::vector<Mat> |
| 17104896 | 0x1050000 | (cv::ACCESS_READ+cv::STD_VECTOR_MAT) std::vector<Mat> |
| 1124007936 | 0x42ff0000 | cv::MAGIC_VAL |
| -2130509812 | 2164457484 | 0x8103000c | std::vector<cv::Point2i> (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| -1040056315 | 3254910981 | 0xc2020005 | cv::Vec4f (cv::ACCESS_WRITE+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U) |
| -1056833530 | 3238133766 | 0xc1020006 | cv::Vec4d (cv::ACCESS_READ+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -2130509812 | 0x8103000c | (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| -2113732596 | 0x8203000c | (cv::ACCESS_WRITE+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| -1056833531 | 0xc1020005 | (cv::ACCESS_READ+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U) |
| -1040056315 | 0xc2020005 | (cv::ACCESS_WRITE+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U) |
| -1056833530 | 0xc1020006 | (cv::ACCESS_READ+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -1040056314 | 0xc2020006 | (cv::ACCESS_WRITE+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| 1072693248 | 0x3ff00000 | double-high:1 | 1073741824 | 0x40000000 | double-high:2 | 1074266112 | 0x40080000 | double-high:3 |
| 1074790400 | 0x40100000 | double-high:4 | 1075052544 | 0x40140000 | double-high:5 | 1075314688 | 0x40180000 | double-high:6 |
| 1075576832 | 0x401c0000 | double-high:7 | 1075838976 | 0x40200000 | double-high:8 | 1075970048 | 0x40220000 | double-high:9 |
| 1076101120 | 0x40240000 | double-high:10 | 1076232192 | 0x40260000 | double-high:11 | 1076363264 | 0x40280000 | double-high:12 |
| 1076494336 | 0x402a0000 | double-high:13 | 1076625408 | 0x402c0000 | double-high:14 | 1076756480 | 0x402e0000 | double-high:15 |
| 1076887552 | 0x40300000 | double-high:16 | 1076953088 | 0x40310000 | double-high:17 | 1077018624 | 0x40320000 | double-high:18 |
| 1077084160 | 0x40330000 | double-high:19 | 1077149696 | 0x40340000 | double-high:20 | 1077215232 | 0x40350000 | double-high:21 |
| 1077280768 | 0x40360000 | double-high:22 | 1077346304 | 0x40370000 | double-high:23 | 1077411840 | 0x40380000 | double-high:24 |
| 1077477376 | 0x40390000 | double-high:25 | 1077542912 | 0x403a0000 | double-high:26 | 1077608448 | 0x403b0000 | double-high:27 |
| 1077673984 | 0x403c0000 | double-high:28 | 1077739520 | 0x403d0000 | double-high:29 | 1077805056 | 0x403e0000 | double-high:30 |
| 1077870592 | 0x403f0000 | double-high:31 | 1077936128 | 0x40400000 | double-high:32 | 1077968896 | 0x40408000 | double-high:33 |
| 1078001664 | 0x40410000 | double-high:34 | 1078034432 | 0x40418000 | double-high:35 | 1078067200 | 0x40420000 | double-high:36 |
| 1078099968 | 0x40428000 | double-high:37 | 1078132736 | 0x40430000 | double-high:38 | 1078165504 | 0x40438000 | double-high:39 |
| 1078198272 | 0x40440000 | double-high:40 | 1078231040 | 0x40448000 | double-high:41 | 1078263808 | 0x40450000 | double-high:42 |
| 1078296576 | 0x40458000 | double-high:43 | 1078329344 | 0x40460000 | double-high:44 | 1078362112 | 0x40468000 | double-high:45 |
| 1078394880 | 0x40470000 | double-high:46 | 1078427648 | 0x40478000 | double-high:47 | 1078460416 | 0x40480000 | double-high:48 |
| 1078493184 | 0x40488000 | double-high:49 | 1078525952 | 0x40490000 | double-high:50 | 1078558720 | 0x40498000 | double-high:51 |
| 1078591488 | 0x404a0000 | double-high:52 | 1078624256 | 0x404a8000 | double-high:53 | 1078657024 | 0x404b0000 | double-high:54 |
| 1078689792 | 0x404b8000 | double-high:55 | 1078722560 | 0x404c0000 | double-high:56 | 1078755328 | 0x404c8000 | double-high:57 |
| 1078788096 | 0x404d0000 | double-high:58 | 1078820864 | 0x404d8000 | double-high:59 | 1078853632 | 0x404e0000 | double-high:60 |
| 1078886400 | 0x404e8000 | double-high:61 | 1078919168 | 0x404f0000 | double-high:62 | 1078951936 | 0x404f8000 | double-high:63 |
| 1078984704 | 0x40500000 | double-high:64 | 1079001088 | 0x40504000 | double-high:65 | 1079017472 | 0x40508000 | double-high:66 |
| 1079033856 | 0x4050c000 | double-high:67 | 1079050240 | 0x40510000 | double-high:68 | 1079066624 | 0x40514000 | double-high:69 |
| 1079083008 | 0x40518000 | double-high:70 | 1079099392 | 0x4051c000 | double-high:71 | 1079115776 | 0x40520000 | double-high:72 |
| 1079132160 | 0x40524000 | double-high:73 | 1079148544 | 0x40528000 | double-high:74 | 1079164928 | 0x4052c000 | double-high:75 |
| 1079181312 | 0x40530000 | double-high:76 | 1079197696 | 0x40534000 | double-high:77 | 1079214080 | 0x40538000 | double-high:78 |
| 1079230464 | 0x4053c000 | double-high:79 | 1079246848 | 0x40540000 | double-high:80 | 1079263232 | 0x40544000 | double-high:81 |
| 1079279616 | 0x40548000 | double-high:82 | 1079296000 | 0x4054c000 | double-high:83 | 1079312384 | 0x40550000 | double-high:84 |
| 1079328768 | 0x40554000 | double-high:85 | 1079345152 | 0x40558000 | double-high:86 | 1079361536 | 0x4055c000 | double-high:87 |
| 1079377920 | 0x40560000 | double-high:88 | 1079394304 | 0x40564000 | double-high:89 | 1079410688 | 0x40568000 | double-high:90 |
| 1079427072 | 0x4056c000 | double-high:91 | 1079443456 | 0x40570000 | double-high:92 | 1079459840 | 0x40574000 | double-high:93 |
| 1079476224 | 0x40578000 | double-high:94 | 1079492608 | 0x4057c000 | double-high:95 | 1079508992 | 0x40580000 | double-high:96 |
| 1079525376 | 0x40584000 | double-high:97 | 1079541760 | 0x40588000 | double-high:98 | 1079558144 | 0x4058c000 | double-high:99 |
| 1079574528 | 0x40590000 | double-high:100 | 1079590912 | 0x40594000 | double-high:101 | 1079607296 | 0x40598000 | double-high:102 |
| 1079623680 | 0x4059c000 | double-high:103 | 1079640064 | 0x405a0000 | double-high:104 | 1079656448 | 0x405a4000 | double-high:105 |
| 1079672832 | 0x405a8000 | double-high:106 | 1079689216 | 0x405ac000 | double-high:107 | 1079705600 | 0x405b0000 | double-high:108 |
| 1079721984 | 0x405b4000 | double-high:109 | 1079738368 | 0x405b8000 | double-high:110 | 1079754752 | 0x405bc000 | double-high:111 |
| 1079771136 | 0x405c0000 | double-high:112 | 1079787520 | 0x405c4000 | double-high:113 | 1079803904 | 0x405c8000 | double-high:114 |
| 1079820288 | 0x405cc000 | double-high:115 | 1079836672 | 0x405d0000 | double-high:116 | 1079853056 | 0x405d4000 | double-high:117 |
| 1079869440 | 0x405d8000 | double-high:118 | 1079885824 | 0x405dc000 | double-high:119 | 1079902208 | 0x405e0000 | double-high:120 |
| 1079918592 | 0x405e4000 | double-high:121 | 1079934976 | 0x405e8000 | double-high:122 | 1079951360 | 0x405ec000 | double-high:123 |
| 1079967744 | 0x405f0000 | double-high:124 | 1079984128 | 0x405f4000 | double-high:125 | 1080000512 | 0x405f8000 | double-high:126 |
| 1080016896 | 0x405fc000 | double-high:127 | 1080033280 | 0x40600000 | double-high:128 | 1080041472 | 0x40602000 | double-high:129 |
| 1080049664 | 0x40604000 | double-high:130 | 1080057856 | 0x40606000 | double-high:131 | 1080066048 | 0x40608000 | double-high:132 |
| 1080074240 | 0x4060a000 | double-high:133 | 1080082432 | 0x4060c000 | double-high:134 | 1080090624 | 0x4060e000 | double-high:135 |
| 1080098816 | 0x40610000 | double-high:136 | 1080107008 | 0x40612000 | double-high:137 | 1080115200 | 0x40614000 | double-high:138 |
| 1080123392 | 0x40616000 | double-high:139 | 1080131584 | 0x40618000 | double-high:140 | 1080139776 | 0x4061a000 | double-high:141 |
| 1080147968 | 0x4061c000 | double-high:142 | 1080156160 | 0x4061e000 | double-high:143 | 1080164352 | 0x40620000 | double-high:144 |
| 1080172544 | 0x40622000 | double-high:145 | 1080180736 | 0x40624000 | double-high:146 | 1080188928 | 0x40626000 | double-high:147 |
| 1080197120 | 0x40628000 | double-high:148 | 1080205312 | 0x4062a000 | double-high:149 | 1080213504 | 0x4062c000 | double-high:150 |
| 1080221696 | 0x4062e000 | double-high:151 | 1080229888 | 0x40630000 | double-high:152 | 1080238080 | 0x40632000 | double-high:153 |
| 1080246272 | 0x40634000 | double-high:154 | 1080254464 | 0x40636000 | double-high:155 | 1080262656 | 0x40638000 | double-high:156 |
| 1080270848 | 0x4063a000 | double-high:157 | 1080279040 | 0x4063c000 | double-high:158 | 1080287232 | 0x4063e000 | double-high:159 |
| 1080295424 | 0x40640000 | double-high:160 | 1080303616 | 0x40642000 | double-high:161 | 1080311808 | 0x40644000 | double-high:162 |
| 1080320000 | 0x40646000 | double-high:163 | 1080328192 | 0x40648000 | double-high:164 | 1080336384 | 0x4064a000 | double-high:165 |
| 1080344576 | 0x4064c000 | double-high:166 | 1080352768 | 0x4064e000 | double-high:167 | 1080360960 | 0x40650000 | double-high:168 |
| 1080369152 | 0x40652000 | double-high:169 | 1080377344 | 0x40654000 | double-high:170 | 1080385536 | 0x40656000 | double-high:171 |
| 1080393728 | 0x40658000 | double-high:172 | 1080401920 | 0x4065a000 | double-high:173 | 1080410112 | 0x4065c000 | double-high:174 |
| 1080418304 | 0x4065e000 | double-high:175 | 1080426496 | 0x40660000 | double-high:176 | 1080434688 | 0x40662000 | double-high:177 |
| 1080442880 | 0x40664000 | double-high:178 | 1080451072 | 0x40666000 | double-high:179 | 1080459264 | 0x40668000 | double-high:180 |
| 1080467456 | 0x4066a000 | double-high:181 | 1080475648 | 0x4066c000 | double-high:182 | 1080483840 | 0x4066e000 | double-high:183 |
| 1080492032 | 0x40670000 | double-high:184 | 1080500224 | 0x40672000 | double-high:185 | 1080508416 | 0x40674000 | double-high:186 |
| 1080516608 | 0x40676000 | double-high:187 | 1080524800 | 0x40678000 | double-high:188 | 1080532992 | 0x4067a000 | double-high:189 |
| 1080541184 | 0x4067c000 | double-high:190 | 1080549376 | 0x4067e000 | double-high:191 | 1080557568 | 0x40680000 | double-high:192 |
| 1080565760 | 0x40682000 | double-high:193 | 1080573952 | 0x40684000 | double-high:194 | 1080582144 | 0x40686000 | double-high:195 |
| 1080590336 | 0x40688000 | double-high:196 | 1080598528 | 0x4068a000 | double-high:197 | 1080606720 | 0x4068c000 | double-high:198 |
| 1080614912 | 0x4068e000 | double-high:199 | 1080623104 | 0x40690000 | double-high:200 | 1080631296 | 0x40692000 | double-high:201 |
| 1080639488 | 0x40694000 | double-high:202 | 1080647680 | 0x40696000 | double-high:203 | 1080655872 | 0x40698000 | double-high:204 |
| 1080664064 | 0x4069a000 | double-high:205 | 1080672256 | 0x4069c000 | double-high:206 | 1080680448 | 0x4069e000 | double-high:207 |
| 1080688640 | 0x406a0000 | double-high:208 | 1080696832 | 0x406a2000 | double-high:209 | 1080705024 | 0x406a4000 | double-high:210 |
| 1080713216 | 0x406a6000 | double-high:211 | 1080721408 | 0x406a8000 | double-high:212 | 1080729600 | 0x406aa000 | double-high:213 |
| 1080737792 | 0x406ac000 | double-high:214 | 1080745984 | 0x406ae000 | double-high:215 | 1080754176 | 0x406b0000 | double-high:216 |
| 1080762368 | 0x406b2000 | double-high:217 | 1080770560 | 0x406b4000 | double-high:218 | 1080778752 | 0x406b6000 | double-high:219 |
| 1080786944 | 0x406b8000 | double-high:220 | 1080795136 | 0x406ba000 | double-high:221 | 1080803328 | 0x406bc000 | double-high:222 |
| 1080811520 | 0x406be000 | double-high:223 | 1080819712 | 0x406c0000 | double-high:224 | 1080827904 | 0x406c2000 | double-high:225 |
| 1080836096 | 0x406c4000 | double-high:226 | 1080844288 | 0x406c6000 | double-high:227 | 1080852480 | 0x406c8000 | double-high:228 |
| 1080860672 | 0x406ca000 | double-high:229 | 1080868864 | 0x406cc000 | double-high:230 | 1080877056 | 0x406ce000 | double-high:231 |
| 1080885248 | 0x406d0000 | double-high:232 | 1080893440 | 0x406d2000 | double-high:233 | 1080901632 | 0x406d4000 | double-high:234 |
| 1080909824 | 0x406d6000 | double-high:235 | 1080918016 | 0x406d8000 | double-high:236 | 1080926208 | 0x406da000 | double-high:237 |
| 1080934400 | 0x406dc000 | double-high:238 | 1080942592 | 0x406de000 | double-high:239 | 1080950784 | 0x406e0000 | double-high:240 |
| 1080958976 | 0x406e2000 | double-high:241 | 1080967168 | 0x406e4000 | double-high:242 | 1080975360 | 0x406e6000 | double-high:243 |
| 1080983552 | 0x406e8000 | double-high:244 | 1080991744 | 0x406ea000 | double-high:245 | 1080999936 | 0x406ec000 | double-high:246 |
| 1081008128 | 0x406ee000 | double-high:247 | 1081016320 | 0x406f0000 | double-high:248 | 1081024512 | 0x406f2000 | double-high:249 |
| 1081032704 | 0x406f4000 | double-high:250 | 1081040896 | 0x406f6000 | double-high:251 | 1081049088 | 0x406f8000 | double-high:252 |
| 1081057280 | 0x406fa000 | double-high:253 | 1081065472 | 0x406fc000 | double-high:254 | 1081073664 | 0x406fe000 | double-high:255 |
| 1081081856 | 0x40700000 | double-high:256 | ||||||
| 1065353216 | 0x3f800000 | float:1 | 1073741824 | 0x40000000 | float:2 | 1077936128 | 0x40400000 | float:3 |
| 1082130432 | 0x40800000 | float:4 | 1084227584 | 0x40a00000 | float:5 | 1086324736 | 0x40c00000 | float:6 |
| 1088421888 | 0x40e00000 | float:7 | 1090519040 | 0x41000000 | float:8 | 1091567616 | 0x41100000 | float:9 |
| 1092616192 | 0x41200000 | float:10 | 1093664768 | 0x41300000 | float:11 | 1094713344 | 0x41400000 | float:12 |
| 1095761920 | 0x41500000 | float:13 | 1096810496 | 0x41600000 | float:14 | 1097859072 | 0x41700000 | float:15 |
| 1098907648 | 0x41800000 | float:16 | 1099431936 | 0x41880000 | float:17 | 1099956224 | 0x41900000 | float:18 |
| 1100480512 | 0x41980000 | float:19 | 1101004800 | 0x41a00000 | float:20 | 1101529088 | 0x41a80000 | float:21 |
| 1102053376 | 0x41b00000 | float:22 | 1102577664 | 0x41b80000 | float:23 | 1103101952 | 0x41c00000 | float:24 |
| 1103626240 | 0x41c80000 | float:25 | 1104150528 | 0x41d00000 | float:26 | 1104674816 | 0x41d80000 | float:27 |
| 1105199104 | 0x41e00000 | float:28 | 1105723392 | 0x41e80000 | float:29 | 1106247680 | 0x41f00000 | float:30 |
| 1106771968 | 0x41f80000 | float:31 | 1107296256 | 0x42000000 | float:32 | 1107558400 | 0x42040000 | float:33 |
| 1107820544 | 0x42080000 | float:34 | 1108082688 | 0x420c0000 | float:35 | 1108344832 | 0x42100000 | float:36 |
| 1108606976 | 0x42140000 | float:37 | 1108869120 | 0x42180000 | float:38 | 1109131264 | 0x421c0000 | float:39 |
| 1109393408 | 0x42200000 | float:40 | 1109655552 | 0x42240000 | float:41 | 1109917696 | 0x42280000 | float:42 |
| 1110179840 | 0x422c0000 | float:43 | 1110441984 | 0x42300000 | float:44 | 1110704128 | 0x42340000 | float:45 |
| 1110966272 | 0x42380000 | float:46 | 1111228416 | 0x423c0000 | float:47 | 1111490560 | 0x42400000 | float:48 |
| 1111752704 | 0x42440000 | float:49 | 1112014848 | 0x42480000 | float:50 | 1112276992 | 0x424c0000 | float:51 |
| 1112539136 | 0x42500000 | float:52 | 1112801280 | 0x42540000 | float:53 | 1113063424 | 0x42580000 | float:54 |
| 1113325568 | 0x425c0000 | float:55 | 1113587712 | 0x42600000 | float:56 | 1113849856 | 0x42640000 | float:57 |
| 1114112000 | 0x42680000 | float:58 | 1114374144 | 0x426c0000 | float:59 | 1114636288 | 0x42700000 | float:60 |
| 1114898432 | 0x42740000 | float:61 | 1115160576 | 0x42780000 | float:62 | 1115422720 | 0x427c0000 | float:63 |
| 1115684864 | 0x42800000 | float:64 | 1115815936 | 0x42820000 | float:65 | 1115947008 | 0x42840000 | float:66 |
| 1116078080 | 0x42860000 | float:67 | 1116209152 | 0x42880000 | float:68 | 1116340224 | 0x428a0000 | float:69 |
| 1116471296 | 0x428c0000 | float:70 | 1116602368 | 0x428e0000 | float:71 | 1116733440 | 0x42900000 | float:72 |
| 1116864512 | 0x42920000 | float:73 | 1116995584 | 0x42940000 | float:74 | 1117126656 | 0x42960000 | float:75 |
| 1117257728 | 0x42980000 | float:76 | 1117388800 | 0x429a0000 | float:77 | 1117519872 | 0x429c0000 | float:78 |
| 1117650944 | 0x429e0000 | float:79 | 1117782016 | 0x42a00000 | float:80 | 1117913088 | 0x42a20000 | float:81 |
| 1118044160 | 0x42a40000 | float:82 | 1118175232 | 0x42a60000 | float:83 | 1118306304 | 0x42a80000 | float:84 |
| 1118437376 | 0x42aa0000 | float:85 | 1118568448 | 0x42ac0000 | float:86 | 1118699520 | 0x42ae0000 | float:87 |
| 1118830592 | 0x42b00000 | float:88 | 1118961664 | 0x42b20000 | float:89 | 1119092736 | 0x42b40000 | float:90 |
| 1119223808 | 0x42b60000 | float:91 | 1119354880 | 0x42b80000 | float:92 | 1119485952 | 0x42ba0000 | float:93 |
| 1119617024 | 0x42bc0000 | float:94 | 1119748096 | 0x42be0000 | float:95 | 1119879168 | 0x42c00000 | float:96 |
| 1120010240 | 0x42c20000 | float:97 | 1120141312 | 0x42c40000 | float:98 | 1120272384 | 0x42c60000 | float:99 |
| 1120403456 | 0x42c80000 | float:100 | 1120534528 | 0x42ca0000 | float:101 | 1120665600 | 0x42cc0000 | float:102 |
| 1120796672 | 0x42ce0000 | float:103 | 1120927744 | 0x42d00000 | float:104 | 1121058816 | 0x42d20000 | float:105 |
| 1121189888 | 0x42d40000 | float:106 | 1121320960 | 0x42d60000 | float:107 | 1121452032 | 0x42d80000 | float:108 |
| 1121583104 | 0x42da0000 | float:109 | 1121714176 | 0x42dc0000 | float:110 | 1121845248 | 0x42de0000 | float:111 |
| 1121976320 | 0x42e00000 | float:112 | 1122107392 | 0x42e20000 | float:113 | 1122238464 | 0x42e40000 | float:114 |
| 1122369536 | 0x42e60000 | float:115 | 1122500608 | 0x42e80000 | float:116 | 1122631680 | 0x42ea0000 | float:117 |
| 1122762752 | 0x42ec0000 | float:118 | 1122893824 | 0x42ee0000 | float:119 | 1123024896 | 0x42f00000 | float:120 |
| 1123155968 | 0x42f20000 | float:121 | 1123287040 | 0x42f40000 | float:122 | 1123418112 | 0x42f60000 | float:123 |
| 1123549184 | 0x42f80000 | float:124 | 1123680256 | 0x42fa0000 | float:125 | 1123811328 | 0x42fc0000 | float:126 |
| 1123942400 | 0x42fe0000 | float:127 | 1124073472 | 0x43000000 | float:128 | 1124139008 | 0x43010000 | float:129 |
| 1124204544 | 0x43020000 | float:130 | 1124270080 | 0x43030000 | float:131 | 1124335616 | 0x43040000 | float:132 |
| 1124401152 | 0x43050000 | float:133 | 1124466688 | 0x43060000 | float:134 | 1124532224 | 0x43070000 | float:135 |
| 1124597760 | 0x43080000 | float:136 | 1124663296 | 0x43090000 | float:137 | 1124728832 | 0x430a0000 | float:138 |
| 1124794368 | 0x430b0000 | float:139 | 1124859904 | 0x430c0000 | float:140 | 1124925440 | 0x430d0000 | float:141 |
| 1124990976 | 0x430e0000 | float:142 | 1125056512 | 0x430f0000 | float:143 | 1125122048 | 0x43100000 | float:144 |
| 1125187584 | 0x43110000 | float:145 | 1125253120 | 0x43120000 | float:146 | 1125318656 | 0x43130000 | float:147 |
| 1125384192 | 0x43140000 | float:148 | 1125449728 | 0x43150000 | float:149 | 1125515264 | 0x43160000 | float:150 |
| 1125580800 | 0x43170000 | float:151 | 1125646336 | 0x43180000 | float:152 | 1125711872 | 0x43190000 | float:153 |
| 1125777408 | 0x431a0000 | float:154 | 1125842944 | 0x431b0000 | float:155 | 1125908480 | 0x431c0000 | float:156 |
| 1125974016 | 0x431d0000 | float:157 | 1126039552 | 0x431e0000 | float:158 | 1126105088 | 0x431f0000 | float:159 |
| 1126170624 | 0x43200000 | float:160 | 1126236160 | 0x43210000 | float:161 | 1126301696 | 0x43220000 | float:162 |
| 1126367232 | 0x43230000 | float:163 | 1126432768 | 0x43240000 | float:164 | 1126498304 | 0x43250000 | float:165 |
| 1126563840 | 0x43260000 | float:166 | 1126629376 | 0x43270000 | float:167 | 1126694912 | 0x43280000 | float:168 |
| 1126760448 | 0x43290000 | float:169 | 1126825984 | 0x432a0000 | float:170 | 1126891520 | 0x432b0000 | float:171 |
| 1126957056 | 0x432c0000 | float:172 | 1127022592 | 0x432d0000 | float:173 | 1127088128 | 0x432e0000 | float:174 |
| 1127153664 | 0x432f0000 | float:175 | 1127219200 | 0x43300000 | float:176 | 1127284736 | 0x43310000 | float:177 |
| 1127350272 | 0x43320000 | float:178 | 1127415808 | 0x43330000 | float:179 | 1127481344 | 0x43340000 | float:180 |
| 1127546880 | 0x43350000 | float:181 | 1127612416 | 0x43360000 | float:182 | 1127677952 | 0x43370000 | float:183 |
| 1127743488 | 0x43380000 | float:184 | 1127809024 | 0x43390000 | float:185 | 1127874560 | 0x433a0000 | float:186 |
| 1127940096 | 0x433b0000 | float:187 | 1128005632 | 0x433c0000 | float:188 | 1128071168 | 0x433d0000 | float:189 |
| 1128136704 | 0x433e0000 | float:190 | 1128202240 | 0x433f0000 | float:191 | 1128267776 | 0x43400000 | float:192 |
| 1128333312 | 0x43410000 | float:193 | 1128398848 | 0x43420000 | float:194 | 1128464384 | 0x43430000 | float:195 |
| 1128529920 | 0x43440000 | float:196 | 1128595456 | 0x43450000 | float:197 | 1128660992 | 0x43460000 | float:198 |
| 1128726528 | 0x43470000 | float:199 | 1128792064 | 0x43480000 | float:200 | 1128857600 | 0x43490000 | float:201 |
| 1128923136 | 0x434a0000 | float:202 | 1128988672 | 0x434b0000 | float:203 | 1129054208 | 0x434c0000 | float:204 |
| 1129119744 | 0x434d0000 | float:205 | 1129185280 | 0x434e0000 | float:206 | 1129250816 | 0x434f0000 | float:207 |
| 1129316352 | 0x43500000 | float:208 | 1129381888 | 0x43510000 | float:209 | 1129447424 | 0x43520000 | float:210 |
| 1129512960 | 0x43530000 | float:211 | 1129578496 | 0x43540000 | float:212 | 1129644032 | 0x43550000 | float:213 |
| 1129709568 | 0x43560000 | float:214 | 1129775104 | 0x43570000 | float:215 | 1129840640 | 0x43580000 | float:216 |
| 1129906176 | 0x43590000 | float:217 | 1129971712 | 0x435a0000 | float:218 | 1130037248 | 0x435b0000 | float:219 |
| 1130102784 | 0x435c0000 | float:220 | 1130168320 | 0x435d0000 | float:221 | 1130233856 | 0x435e0000 | float:222 |
| 1130299392 | 0x435f0000 | float:223 | 1130364928 | 0x43600000 | float:224 | 1130430464 | 0x43610000 | float:225 |
| 1130496000 | 0x43620000 | float:226 | 1130561536 | 0x43630000 | float:227 | 1130627072 | 0x43640000 | float:228 |
| 1130692608 | 0x43650000 | float:229 | 1130758144 | 0x43660000 | float:230 | 1130823680 | 0x43670000 | float:231 |
| 1130889216 | 0x43680000 | float:232 | 1130954752 | 0x43690000 | float:233 | 1131020288 | 0x436a0000 | float:234 |
| 1131085824 | 0x436b0000 | float:235 | 1131151360 | 0x436c0000 | float:236 | 1131216896 | 0x436d0000 | float:237 |
| 1131282432 | 0x436e0000 | float:238 | 1131347968 | 0x436f0000 | float:239 | 1131413504 | 0x43700000 | float:240 |
| 1131479040 | 0x43710000 | float:241 | 1131544576 | 0x43720000 | float:242 | 1131610112 | 0x43730000 | float:243 |
| 1131675648 | 0x43740000 | float:244 | 1131741184 | 0x43750000 | float:245 | 1131806720 | 0x43760000 | float:246 |
| 1131872256 | 0x43770000 | float:247 | 1131937792 | 0x43780000 | float:248 | 1132003328 | 0x43790000 | float:249 |
| 1132068864 | 0x437a0000 | float:250 | 1132134400 | 0x437b0000 | float:251 | 1132199936 | 0x437c0000 | float:252 |
| 1132265472 | 0x437d0000 | float:253 | 1132331008 | 0x437e0000 | float:254 | 1132396544 | 0x437f0000 | float:255 |
| 1132462080 | 0x43800000 | float:256 |
| -2130509812 | 0x8103000c | (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| -2130509811 | 0x8103000d | (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| -2113732587 | 0x82030015 | (cv::ACCESS_WRITE+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_32S) |
| -2130444276 | 0x8104000c | (cv::ACCESS_READ+cv::STD_VECTOR_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| 16842817 | 0x1010041 | (cv::ACCESS_READ+cv::MAT+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_64F) |
| 17301504 | 0x1080000 | (cv::ACCESS_READ+cv::CUDA_HOST_MEM) |
| -2113667060 | 0x8204000c | (cv::ACCESS_WRITE+cv::STD_VECTOR_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
| 33619968 | 0x2010000 | (cv::ACCESS_WRITE+cv::MAT) |
| 16842752 | 0x1010000 | (cv::ACCESS_READ+cv::MAT) |
| 50397184 | 0x3010000 | (cv::ACCESS_READ+cv::ACCESS_WRITE+cv::MAT) |
| -1040121856 | 0xc2010000 | (cv::ACCESS_WRITE+cv::MAT+cv::FIXED_TYPE+cv::FIXED_SIZE) |
| -1040121856 | 0xc2010000 | (cv::ACCESS_WRITE+cv::MAT+cv::FIXED_TYPE+cv::FIXED_SIZE) |
| 33882112 | 0x2050000 | (cv::ACCESS_WRITE+cv::STD_VECTOR_MAT) |
| 17104896 | 0x1050000 | (cv::ACCESS_READ+cv::STD_VECTOR_MAT) |
| -1040056315 | 0xc2020005 | (cv::ACCESS_WRITE+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U) |
| -1056833530 | 0xc1020006 | (cv::ACCESS_READ+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -1056833530 | 0xc1020006 | (cv::ACCESS_READ+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -1040056314 | 0xc2020006 | (cv::ACCESS_WRITE+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -1040056314 | 0xc2020006 | (cv::ACCESS_WRITE+cv::MATX+cv::FIXED_TYPE+cv::FIXED_SIZE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| 33685504 | 0x2020000 | (cv::ACCESS_WRITE+cv::MATX) |
| -1056571392 | 0xc1060000 | (cv::ACCESS_READ+cv::EXPR+cv::FIXED_TYPE+cv::FIXED_SIZE) |
| 50987008 | 0x30a0000 | (cv::ACCESS_READ+cv::ACCESS_WRITE+cv::UMAT) |
| 34209792 | 0x20a0000 | (cv::ACCESS_WRITE+cv::UMAT) |
| 17432576 | 0x10a0000 | (cv::ACCESS_READ+cv::UMAT) |
| -2113732604 | 0x82030004 | (cv::ACCESS_WRITE+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U) |
| -2130509820 | 0x81030004 | (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_16U) |
| -2113732602 | 0x82030006 | (cv::ACCESS_WRITE+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -2130509818 | 0x81030006 | (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_8S+cv::DEPTH_MASK_16U) |
| -2130509811 | 0x8103000d | (cv::ACCESS_READ+cv::STD_VECTOR+cv::FIXED_TYPE+cv::DEPTH_MASK_8U+cv::DEPTH_MASK_16U+cv::DEPTH_MASK_16S) |
#include <iostream>
#include <Windows.h>
#include <assert.h>
#include <opencv2/opencv.hpp>
#include <stdio.h>
#include <process.h>
#include <io.h>
#include <direct.h>
#include <vld.h>
#include "../testwin.h"
#include <Shlwapi.h>
#pragma comment(lib, "shlwapi.lib") // Windows API PathFileExists
#include "../../dcode/enhancedef.h"
#include <ncnn/mat.h>
#include <ncnn/allocator.h>
#include <ncnn/cpu.h>
#include <ncnn/net.h>
enum {
KIND_SHIFT = 16,
FIXED_TYPE = 0x8000 << KIND_SHIFT,
FIXED_SIZE = 0x4000 << KIND_SHIFT,
KIND_MASK = 31 << KIND_SHIFT,
NONE = 0 << KIND_SHIFT,
MAT = 1 << KIND_SHIFT,
MATX = 2 << KIND_SHIFT,
STD_VECTOR = 3 << KIND_SHIFT,
STD_VECTOR_VECTOR = 4 << KIND_SHIFT,
STD_VECTOR_MAT = 5 << KIND_SHIFT,
EXPR = 6 << KIND_SHIFT,
OPENGL_BUFFER = 7 << KIND_SHIFT,
CUDA_HOST_MEM = 8 << KIND_SHIFT,
CUDA_GPU_MAT = 9 << KIND_SHIFT,
UMAT = 10 << KIND_SHIFT,
STD_VECTOR_UMAT = 11 << KIND_SHIFT,
STD_BOOL_VECTOR = 12 << KIND_SHIFT,
STD_VECTOR_CUDA_GPU_MAT = 13 << KIND_SHIFT,
STD_ARRAY = 14 << KIND_SHIFT,
STD_ARRAY_MAT = 15 << KIND_SHIFT
};
enum {
ACCESS_READ = 1 << 24, ACCESS_WRITE = 1 << 25,
ACCESS_RW = 3 << 24, ACCESS_FAST = 1 << 26
};
enum
{
DEPTH_MASK_8U = 1 << CV_8U,
DEPTH_MASK_8S = 1 << CV_8S,
DEPTH_MASK_16U = 1 << CV_16U,
DEPTH_MASK_16S = 1 << CV_16S,
DEPTH_MASK_32S = 1 << CV_32S,
DEPTH_MASK_32F = 1 << CV_32F,
DEPTH_MASK_64F = 1 << CV_64F,
DEPTH_MASK_ALL = (DEPTH_MASK_64F << 1) - 1,
DEPTH_MASK_ALL_BUT_8S = DEPTH_MASK_ALL & ~DEPTH_MASK_8S,
DEPTH_MASK_FLT = DEPTH_MASK_32F + DEPTH_MASK_64F
};
#define PARSE_CHECK(mat) if (knum & mat) { \
unsigned int znum = knum & (~mat); \
if (!code) { \
printf("parse - cv::" #mat " %08x %08x/%08x \n", mat, knum, znum); } \
knum = znum; strcat(buffer, "+cv::" #mat); check += mat; \
} assert(getBinCount(mat) == 1);
#define PARSE_CHECK_KIND(mat) if ((knum & (KIND_MASK)) == mat) { \
unsigned int znum = knum & (~(KIND_MASK)); \
if (!code) { \
printf("parse - cv::" #mat " %08x %08x/%08x \n", mat, knum, znum); } \
knum = znum; strcat(buffer, "+cv::" #mat); check += mat; \
}
int getBinCount(const unsigned int src) {
int count = 0;
unsigned int knum = src;
while (knum) {
if (knum & 1) {
count++;
}
knum = knum >> 1;
}
if (count != 1) {
assert(count == 1);
}
return count;
}
//#include "E:\kSource\blog\invisible\decompile\mycv.h"
int parseCvMagic(unsigned int knum, bool code = false) {
if (!code) {
printf("---------- \n");
}
const unsigned int src = knum;
unsigned int check = 0; // 累加上去。
char buffer[1024] = { 0 };
enum { MAGIC_VAL = 0x42FF0000, AUTO_STEP = 0, CONTINUOUS_FLAG = CV_MAT_CONT_FLAG, SUBMATRIX_FLAG = CV_SUBMAT_FLAG };
enum { MAGIC_MASK = 0xFFFF0000, TYPE_MASK = 0x00000FFF, DEPTH_MASK = 7 };
unsigned int cont = CV_MAT_CONT_FLAG;
unsigned int submat = CV_SUBMAT_FLAG;
PARSE_CHECK(CV_MAT_CONT_FLAG);
PARSE_CHECK(CV_SUBMAT_FLAG);
CV_UNUSED(cont);
CV_UNUSED(submat);
PARSE_CHECK(ACCESS_READ);
PARSE_CHECK(ACCESS_WRITE);
//PARSE_CHECK(ACCESS_RW);
PARSE_CHECK(ACCESS_FAST);
PARSE_CHECK_KIND(MAT);
PARSE_CHECK_KIND(MATX);
PARSE_CHECK_KIND(STD_VECTOR);
PARSE_CHECK_KIND(STD_VECTOR_VECTOR);
PARSE_CHECK_KIND(STD_VECTOR_MAT);
PARSE_CHECK_KIND(EXPR);
PARSE_CHECK_KIND(OPENGL_BUFFER);
PARSE_CHECK_KIND(CUDA_HOST_MEM);
PARSE_CHECK_KIND(CUDA_GPU_MAT);
PARSE_CHECK_KIND(UMAT);
PARSE_CHECK_KIND(STD_VECTOR_UMAT);
PARSE_CHECK_KIND(STD_BOOL_VECTOR);
PARSE_CHECK_KIND(STD_VECTOR_CUDA_GPU_MAT);
PARSE_CHECK_KIND(STD_ARRAY);
PARSE_CHECK_KIND(STD_ARRAY_MAT);
PARSE_CHECK(FIXED_TYPE);
PARSE_CHECK(FIXED_SIZE);
PARSE_CHECK(DEPTH_MASK_8U);
PARSE_CHECK(DEPTH_MASK_8S);
PARSE_CHECK(DEPTH_MASK_16U);
PARSE_CHECK(DEPTH_MASK_16S);
PARSE_CHECK(DEPTH_MASK_32S);
PARSE_CHECK(DEPTH_MASK_32F);
PARSE_CHECK(DEPTH_MASK_64F);
//PARSE_CHECK(DEPTH_MASK_ALL);
//PARSE_CHECK(DEPTH_MASK_ALL_BUT_8S);
//PARSE_CHECK(DEPTH_MASK_FLT);
unsigned int xtype = knum & TYPE_MASK;
if (xtype) {
assert(xtype == 0);
}
unsigned int magic = knum & MAGIC_MASK;
if (magic) {
assert(magic == 0);
}
unsigned int depth = knum & DEPTH_MASK;
if (depth) {
assert(depth == 0);
}
if (knum == 0) { // 用完了。
printf("%d | 0x%x | (%s) \n", src, src, &buffer[1]);
} else { // 有剩余 !!!
printf("%d | 0x%x | (%s | 0x%x) \n", src, src, &buffer[1], knum);
}
if (check != src || knum != 0) {
assert(check + knum == src);
assert(check == src);
assert(knum == 0);
}
return knum;
}
void testmagic() {
int k = 0;
k = sizeof(cv::Size); // 8
k = sizeof(std::vector<int>); // 16
k = sizeof(cv::Mat); // 56
k = sizeof(std::initializer_list<int>); // 8
k = sizeof(std::array<int, 2>); // 8
k = sizeof(cv::Vec<int, 2>); // 8
k = sizeof(cv::Matx<int, 2, 3>); // 24
k = sizeof(cv::Point_<int>); // 8
k = sizeof(cv::Point3_<int>); // 12
k = sizeof(cv::MatCommaInitializer_<int>); // 20
cv::Vec4d vec;
cv::InputArray array(vec);
k = array.getFlags();
parseCvMagic(k, true);
parseCvMagic(33619968, true);
parseCvMagic(16842752, true);
parseCvMagic(33882112, true);
parseCvMagic(17104896, true);
parseCvMagic(-2130509812, true);
parseCvMagic(-1040056315, true);
parseCvMagic(-1056833530, true);
// 这几个存在疑问。
parseCvMagic(1072693248, true);
parseCvMagic(1074266112, true);
parseCvMagic(1081073664, true);
parseCvMagic(1079623680, true);
}
int main(int argc, char *argv[])
{
testmagic();
printf("ok");
getchar();
return 0;
}
内存地址是否高位为 1,int64 的情况?可以当成 long long 来处理。
64 位操作系统内存值的最高位可能是 1 吗?不可能,所有系统的寻址能力,最高 0xffff 都是用不到的。
简述 AMD64 架构的各类处理器分页模式,以及什么是物理地址扩展 AMD64 架构核心 —— 长模式分页。
长模式是 AMD64 架构的核心,它使用 48 位长的二进制数表示线性地址。而长模式的分页则是以 PAE 的分页模式作为跳板,将 32 位的线性地址扩展至 48 位,并转换成 52 位长的物理地址。
最高位只有运算的时候,可能用到。一般就是 48 位,启用 PAE 可以到 52 位。
危险的 (unsigned int)(float) 强转:
if (outx == 0) {
auto xxd = v25 * 255.0;
float xxdf = (float)xxd;
int t1 = (int)xxdf;
int t2 = (unsigned int)xxdf; // 这里 32 系统,64 系统不一样。
printf("v25 = %f \n", v25);
printf("v25 = %f \n", xxd);
printf("v25 = %f %x %x:%x \n", xxdf, *(_DWORD*)&xxdf, t1, t2);
printf("v25 = %x %d \n", (unsigned int)xxdf, temp);
}
32 位系统:
v25 = -0.333500
v25 = -85.042499
v25 = -85.042496 c2aa15c2 ffffffab:ffffffff
v25 = ffffffff 255
// 生成的汇编不一样,造成计算误差。
movss xmm0,dword ptr [ebp-0C8h]
call __ftoui3 (0F1B1708h)
mov dword ptr [ebp-0D0h],eax
64 位系统:
v25 = -0.333500
v25 = -85.042499
v25 = -85.042496 c2aa15c2 ffffffab:ffffffab
v25 = ffffffab 171
// 生成的汇编不一样,造成计算误差。
cvttss2si rax,dword ptr [rsp+140h]
mov dword ptr [rsp+148h],eax
6BlackWhiteColor\android\54.webp.result.png – 这玩意每次跑出来结果不一样。
-
由于矩阵没有初始化,造成的结果波动。
memset(bkground.data, 0, bkground.step * bkground.rows);7SaveInk\android\78.jfif.result.png – 这个也不一样。 -
__dmb(0xBu);->__dmb(_ARM_BARRIER_ISH);typedef enum _tag_ARMINTR_BARRIER_TYPE { _ARM_BARRIER_SY = 0xF, _ARM_BARRIER_ST = 0xE, _ARM_BARRIER_ISH = 0xB, _ARM_BARRIER_ISHST = 0xA, _ARM_BARRIER_NSH = 0x7, _ARM_BARRIER_NSHST = 0x6, _ARM_BARRIER_OSH = 0x3, _ARM_BARRIER_OSHST = 0x2 }
cv::_OutputArray
v67.a.dims = 0; // 3
v67.a.flags = 0; // 2
v67.op = (const cv::MatOp*)33619968; // 0
v67.flags = (int)thisz; // 1
// 矩阵初始化代码。需要删除。
matArray[2].flags = 0x42ff0000;
memset(&matArray[2].dims, 0, 0x24u);
matArray[2].step.buf[1] = 0;
matArray[2].step.buf[0] = 0;
matArray[2].step.p = matArray[2].step.buf;
matArray[2].size.p = &matArray[2].rows;
整数定数除法的代换 (constant integer division)
消失的除法指令:Part1
除法换成乘法 3435973837 ![]() 在 gcc 里面有一个 32-bit 的 unsigned integer x,那么
在 gcc 里面有一个 32-bit 的 unsigned integer x,那么 x/10 会被转换成 (x*3435973837)>>35 。
for (int i = 0; i < 10; i++) {
int a = i * 5;
int b = a * 3435973837;
printf("%u %u \n", a, b);
assert(a / 5 == b);
}
为了效率,已经丧心病狂了。
一个 32-bit 的 unsigned integer x,那么 x/10 会被转换成 (x*3435973837)>>35 。
除以 5 等价于 乘以 3435973837(运算溢出后是等价的)。
Shift to divide by 10
深入理解函数内静态局部变量初始化
https://opensource.apple.com/source/libcppabi/libcppabi-14/src/cxa_guard.cxx j___cxa_guard_acquire note The actual code emitted by GCC to call a local static variable's constructor looks something like this:
static <type> guard;
if (!guard.first_byte) {
if (__cxa_guard_acquire (&guard)) {
bool flag = false;
try {
// Do initialization.
__cxa_guard_release (&guard);
flag = true;
// Register variable for destruction at end of program.
} catch {
if (!flag) {
__cxa_guard_abort (&guard);
}
}
}
}
- 如果对象无析构函数(包括不需要合成析构函数,比如注释掉 ~A 和 string s 两行代码)
delete 会直接调用 operator delete 并直接调用 free 释放内存,
这个时候的
new=new [](仅在数量上有差异),delete=delete[]。 - 如果对象存在析构函数(包括合成析构函数),则 这个才是重点 :
new []返回的地址会后移 4 个字节,并用那 4 个存放数组的大小!而 new 不用后移这四个字节。delete []根据那个 4 个字节的值,调用指定次数的析构函数,同样 delete 也不需要那四个字节。
结果就是在不恰当的使用 delete 和 delete [] 调用 free 的时候会造成 4 个字节的错位,
最终导致 debug assertion failed!
再回到《高质量 C++ 编程指南》:
delete []objects; // 正确的用法
delete objects; // 错误的用法
后者相当于 delete objects[0] ,漏掉了另外 99 个对象。
严格应该这样说:后者相当于仅调用了 objects[0] 的析构函数,
漏掉了调用另外 99 个对象的析构函数,
并且在调用之后释放内存时导致异常(如果存在析构函数的话),
如果对象无析构函数该语句与 delete []objects 相同。
new [] :
// 申请大小为 5(4+1,既 4 个字节存放数组大小,一个存放对象大小,0 字节对象大小为 1)
00401298 push 5
// 获取分配的内存地址,存放入 AX
0040129A call operator new (00408660)
0040129F add esp,4
004012A2 mov dword ptr [ebp-8],eax
// 判断是否 =0,既 ==NULL
004012A5 cmp dword ptr [ebp-8],0
004012A9 je main+3Fh (004012bf)
004012AB mov eax,dword ptr [ebp-8]
// !=0,则用前四个自己存放数组大小,测试对象数组大小为 1
004012AE mov dword ptr [eax],1
004012B4 mov ecx,dword ptr [ebp-8]
004012B7 add ecx,4 // 地址值加 4
004012BA mov dword ptr [ebp-14h],ecx
004012BD jmp main+46h (004012c6)
004012BF mov dword ptr [ebp-14h],0 // 分配失败,这是为 0
004012C6 mov edx,dword ptr [ebp-14h]
004012C9 mov dword ptr [ebp-4],edx
delete [] :
00401388 mov edx,dword ptr [ebp-4]
0040138B sub edx,4 // 与 delete 相比,先前移指针然后释放空间。
0040138E push edx
0040138F call operator delete (004063e0)
delete:
0040134F mov ecx,dword ptr [ebp-4]
00401352 push ecx
00401353 call operator delete (00406370)
ARM 原子操作
深入浅出 ARM 原子操作 ![]() __ldrex and __strex intrinsics deprecated
__ldrex and __strex intrinsics deprecated
int sum = 0;
int old = sum;
for (int i = 0; i < 1000000; i++) { // 百万次
// 如果 old 等于 sum,就把 old+1 写入 sum
while (!__sync_bool_compare_and_swap(&sum, old, old + 1)) {
old = sum; // 更新 old
}
}
do {
while ( 1 ) {
__dmb();
do {
v2 = __ldrex((unsigned __int32 *)&sum);
v3 = v2 == v1;
if ( v2 != v1 )
break;
v4 = __strex(v1 + 1, (unsigned int *)&sum);
v3 = v4 == 0;
} while ( v4 );
__dmb();
if ( v3 )
break;
v1 = sum;
}
--v0;
} while ( v0 );
v14 = (unsigned int*)(v13 + 12); // 读取地址。
__dmb(0xBu);
do
v15 = __ldrex(v14); // 读取值,标记独占。
while (__strex(v15 + 1, v14)); // 如果没有设置成功,继续循环。
__dmb(0xBu);
在 ARM 系统当中通过 LDREX 和 STREX 实现内存的原子操作,首先研究一下两条指令的语义。 其实 LDREX 和 STREX 指令,是将单纯的更新内存的原子操作分成了两个独立的步骤。 大致的流程如下,但是 ARM 内部为了实现这个功能,还有不少复杂的情况要处理。
LDREX 用来读取内存中的值,并标记对该段内存的独占访问:LDREX Rx, [Ry] 。
上面的指令意味着,读取寄存器 Ry 指向的 4 字节内存值,将其保存到 Rx 寄存器中,同时标记对 Ry 指向内存区域的独占访问。
如果执行 LDREX 指令的时候发现已经被标记为独占访问了,并不会对指令的执行产生影响。
而 STREX 在更新内存数值时,会检查该段内存是否已经被标记为独占访问,
并以此来决定是否更新内存中的值:STREX Rx, Ry, [Rz] 。
如果执行这条指令的时候发现已经被标记为独占访问了,则将寄存器 Ry 中的值更新到寄存器 Rz 指向的内存,
并将寄存器 Rx 设置成 0。指令执行成功后,会将独占访问标记位清除。
而如果执行这条指令的时候发现没有设置独占标记,则不会更新内存,且将寄存器 Rx 的值设置成 1。
一旦某条 STREX 指令执行成功后,以后再对同一段内存尝试使用 STREX 指令更新的时候,
会发现独占标记已经被清空了,就不能再更新了,从而实现独占访问的机制。
Hey, there! Enjoy!
Hey, there! Welcome to my blog. I hope you enjoy reading the stuff in here. Nothing fancy, really. Just bits and bobs about tech and random topics.
wchar_t* pstr = nullptr;
CString exe = pstr; // 不会崩溃。
exe.Append(L"test");
// 0xC0000005: 读取位置 0x00000000 时发生访问冲突。
std::wstring tempexe = pstr; // 会崩溃。
tempexe.append(L"test");
两个崩溃:
std::string = null;CString str; GetWindowsText(hWnd, str.GetBuffer(/* 没有指定大小 */), MAX_PATH);
bool endsWith(const CString& str, const CString& suffix, bool ignoreCase)
{
int totalSize = str.GetLength();
int suffixSize = suffix.GetLength();
if (totalSize < suffixSize) {
return false;
}
if (ignoreCase) {
return str.Right(suffixSize).CompareNoCase(suffix) == 0;
}
return str.Right(suffixSize).Compare(suffix) == 0;
}
Windows 内存状态:
__int64 winMemoCtrl() {
MEMORYSTATUSEX memory_status;
memory_status.dwLength = sizeof(memory_status);
GlobalMemoryStatusEx(&memory_status);
if (memory_status.ullAvailPhys <= 500 * 1024 * 1024) {
return 30 * 1024 * 1024;
}
return 100 * 1024 * 1024;
}
Android Studio
Android ARGB_8888 格式图片的各通道顺序其实不是 ARGB,而是 RGBA。 这里还真不一定,最后,我是通过设置一个颜色位,0xFF4080C0,然后底层校验判断的。
int* datap = (int*) data;
unsigned char* check = (unsigned char*) data;
// 0xFF4080C0
if (check[3] >= 0xf0 && //
0xf0 > check[0] &&
check[0] > check[1] && //
check[1] > check[2]) {
datap[0] = color;
cv::cvtColor(src, tempmat, cv::COLOR_RGBA2RGB);
// 0xFFC08040
} else if (check[3] >= 0xf0 && //
0xf0 > check[2] &&
check[2] > check[1] && //
check[1] > check[0]) {
// RGBA -> BGRA
char* p = (char*)&color;
char r = *(p+0);
char b = *(p+2);
*(p+0) = b;
*(p+2) = r;
datap[0] = color;
cv::cvtColor(src, tempmat, cv::COLOR_BGRA2RGB);
// 0xffa8bbc2 - 0xff??
} else {
#if defined(_DEBUG) || defined(DEBUG)
throw std::invalid_argument("img data err"); // checked(8Ia6)
#else
return -1;
#endif
}
- E:\android-studio-2021.3.1.17-windows.exe
- 最新版本,老手机(HUAWEI MT7-TL00 Android 5.1.1 API 22)无法调试 C++。
- 新小手机(OPPO PBCM30 Android 10,API 29)可以调试。
- E:\android-studio-20191205-3.5.3-ide-191.6010548-windows.exe
- 无法 load 起来。
- E:\android-studio-20200224-3.6-ide-192.6200805-windows.exe
- 没有过多尝试。
- E:\android-studio-20210119-4.1.2-ide-201.7042882-windows.exe
- 最终貌似是这个版本。
- This version of the Android Support plugin for IntelliJ IDEA (or Android Studio)
cannot open this project, please retry with version 2021.2.1 or newer.
- 不能打开主工程,那玩意太新了。
- No toolchains found in the NDK toolchains folder for ABI with prefix: arm-linux-androideabi
- classpath "com.android.tools.build:gradle:4.1.3"
C:\Users\hawkhai\AppData\Local\Android\Sdk
guide 原版 Android。 result,pc 32 版本,64 作为对照组。 android 文件夹,self android 32 版本,64 作为对照组。
操作系统和编译器预定义宏
操作系统预定义宏:
| 操作系统 | 公共定义 | 64 位系统定义 |
| Windows | _WIN32 | _WIN64 |
| macOS | __APPLE__ | __LP64__ |
| Linux | __linux__ | __LP64__ |
| Android | __ANDROID__ | __LP64__ |
编译器预定义宏(指令集):
| 编译器 | 编译器定义 | x86 | AMD64 | ARM32 | Thumb | ARM64 |
| MSVC | _MSC_VER | _M_IX86 | _M_X64 | _M_ARM | _M_THUMB | _M_ARM64 |
| GCC | __GNUC__ | __i386__ | __x86_64__ | __arm__ | __thumb__ | __aarch64__ |
| Clang | __clang__ | __i386__ | __x86_64__ | __arm__ | __thumb__ | __aarch64__ |
C++ 数据类型
char buffer[1024];
sprintf(buffer, "char | %d \n", sizeof(char));
sprintf(buffer, "short | %d \n", sizeof(short));
sprintf(buffer, "int | %d \n", sizeof(int));
sprintf(buffer, "long | %d \n", sizeof(long));
sprintf(buffer, "long long | %d \n", sizeof(long long));
sprintf(buffer, "__int64 | %d \n", sizeof(__int64));
sprintf(buffer, "float | %d \n", sizeof(float));
sprintf(buffer, "double | %d \n", sizeof(double));
sprintf(buffer, "long double | %d \n", sizeof(long double));
sprintf(buffer, "void* | %d \n", sizeof(void*));
sprintf(buffer, "size_t | %d \n", sizeof(size_t));
- 主要就是指针和 int 的问题。
| 类型 | Win32 | Win64 | Android32 | Android64 | C# |
|---|---|---|---|---|---|
| char | 1 | 1 | 1 | 1 | 2 (wchar) |
| short | 2 | 2 | 2 | 2 | 2 |
| int | 4 | 4 | 4 | 4 | 4 |
| long | 4 | 4 | 4 | 8(巨坑) | 8 |
| long long | 8 | 8 | 8 | 8 | |
| int64 | 8 | 8 | 8 | 8 | |
| float | 4 | 4 | 4 | 4 | 4 |
| double | 8 | 8 | 8 | 8 | 8 |
| long double | 8 | 8 | 8 | 16(巨坑) | |
| void* | 4 | 8 | 4 | 8 | |
| size_t | 4 | 8 | 4 | 8 |
note
补码最大好处就是不管是有符号数还是无符号数都可以用同一套加减法。
有符号数和无符号数在计算机里表示都是一样的,二进制的补码形式。
是有符号还是无符号,是编译器来辨认的。
- 赋值截断问题
- 等长直接赋值,变短直接截断,变长如果正前补 0,为负前补 1,浮点数同理。
- 运算问题
- 汇编是不区分正负数字的。溢出不溢出,是由程序员判断的,机器不管。
- 溢出标志
OF可检测有符号数的溢出。 - 进位标志
CF可检测无符号数的回绕。
- 溢出标志
- 汇编是不区分正负数字的。溢出不溢出,是由程序员判断的,机器不管。
- 判等问题
movsx eax,byte ptr [a]先符号扩展,再传送。movzx ecx,byte ptr [b]先零扩展,再传送。cmp eax,ecx再比较。
C/C++ 中 float 的内存结构
note ![]() float 的内存结构
一个 32 位的 float 数和一个 64 位 double 数的存储主要分为三部分:符号位,指数位,尾数位。
以 float 数为例:
float 的内存结构
一个 32 位的 float 数和一个 64 位 double 数的存储主要分为三部分:符号位,指数位,尾数位。
以 float 数为例:
- 符号位 (sign):1 个 bit,0 代表正数,1 代表负数(这里和整数一致,所以汇编可以直接判断正负)。
- 指数位 (exponent):8 个 bit,范围 -127~128,用于存储科学计数法中的指数部分,并且采用以为存储方式,所存储的数据为原数据 +127。
- 尾数位 (mantissa):23bit,用于存储尾数部分。
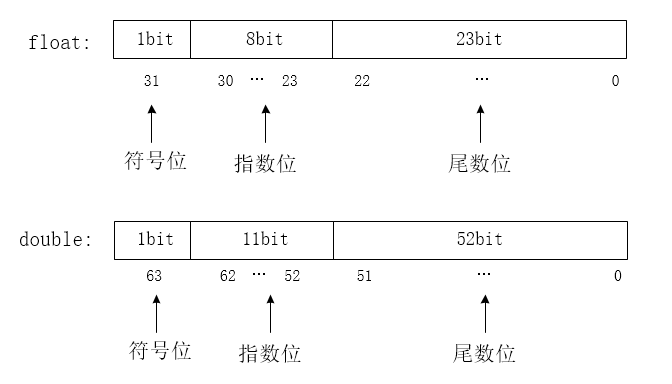
float 数的表示形式: \(pow(−1,sign)*(1+mag)*pow(2,exp−127)\)
剪贴板
#include <windows.h>
#include <iostream>
复制:
if (OpenClipboard())
{
HGLOBAL hGBClipboard;
char *chBufferText;
EmptyClipboard();
hGBClipboard = GlobalAlloc(GMEM_DDESHARE, strClipboardText.GetLength() + 1);
chBufferText = (char*)GlobalLock(hGBClipboard);
strcpy(chBufferText, LPCSTR(strClipboardText));
GlobalUnlock(hGBClipboard);
SetClipboardData(CF_TEXT, hGBClipboard);
CloseClipboard();
}
粘贴:
if (OpenClipboard())
{
HANDLE hClipboardData = GetClipboardData(CF_TEXT);
char *chBufferText = (char*)GlobalLock(hClipboardData);
strClipboardText = chBufferText;
GlobalUnlock(hClipboardData);
CloseClipboard();
}
主线程断言
#include <assert.h>
#include <Windows.h>
#include <TlHelp32.h>
BOOL GetCurrentMainThreadID(DWORD* pdwThreadID)
{
HANDLE hThreadSnap = INVALID_HANDLE_VALUE;
BOOL bRet = FALSE;
THREADENTRY32 te32 = {0};
DWORD dwProcessId = 0;
static DWORD Curl_dwMainThreadId = 0;
if (!pdwThreadID) {
return FALSE;
}
if (Curl_dwMainThreadId) {
*pdwThreadID = Curl_dwMainThreadId;
return TRUE;
}
dwProcessId = GetCurrentProcessId();
// Take a snapshot of all processes in the system.
hThreadSnap = CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, 0);
if (hThreadSnap == INVALID_HANDLE_VALUE) {
return FALSE;
}
// Fill in the size of the structure before using it.
te32.dwSize = sizeof(THREADENTRY32);
if (Thread32First(hThreadSnap, &te32)) {
if (te32.th32OwnerProcessID == dwProcessId) {
*pdwThreadID = te32.th32ThreadID;
Curl_dwMainThreadId = te32.th32ThreadID;
bRet = TRUE;
}
}
while (!bRet && Thread32Next(hThreadSnap, &te32)) {
if (te32.th32OwnerProcessID == dwProcessId) {
*pdwThreadID = te32.th32ThreadID;
Curl_dwMainThreadId = te32.th32ThreadID;
bRet = TRUE;
}
}
// Do not forget to clean up the snapshot object.
CloseHandle (hThreadSnap);
return bRet;
}
void CheckAssertMainThread() {
#if _DEBUG
DWORD dwThreadID = 0;
if (GetCurrentMainThreadID(&dwThreadID)) {
assert(dwThreadID != GetCurrentThreadId());
}
#endif
}
ToySingleInstance.hpp
#pragma once
#ifndef __TOY_SINGLEINSTANCE_H__
#define __TOY_SINGLEINSTANCE_H__
#include <Windows.h>
#include <atlstr.h>
namespace toy
{
class ToySingleInstance
{
public:
ToySingleInstance(LPCTSTR strName)
: m_hMutex(NULL)
, m_strInstanceName(strName) {
}
~ToySingleInstance()
{
Close();
}
BOOL IsExist()
{
HANDLE hMutex = ::OpenMutex(SYNCHRONIZE, FALSE, m_strInstanceName);
if (hMutex) {
::CloseHandle(hMutex);
return TRUE;
}
return FALSE;
}
BOOL Create()
{
if (IsExist())
return FALSE;
HANDLE hMutex = CreateMutex(
NULL,
TRUE,
m_strInstanceName
);
if (hMutex == NULL) {
return FALSE;
} else if (GetLastError() == ERROR_ALREADY_EXISTS) {
::CloseHandle(hMutex);
return FALSE;
}
m_hMutex = hMutex;
hMutex = NULL;
return TRUE;
}
VOID Close()
{
if (m_hMutex) {
CloseHandle(m_hMutex);
m_hMutex = NULL;
}
}
private:
CString m_strInstanceName;
HANDLE m_hMutex;
};
}
#endif
crc64
from opencv ocl.cpp
typedef uint32_t uint;
typedef signed char schar;
typedef unsigned char uchar;
typedef unsigned short ushort;
typedef int64_t int64;
typedef uint64_t uint64;
#define CV_BIG_INT(n) n##LL
#define CV_BIG_UINT(n) n##ULL
// Computes 64-bit "cyclic redundancy check" sum, as specified in ECMA-182
uint64 crc64(const uchar* data, size_t size, uint64 crcx)
{
static uint64 table[256];
static bool initialized = false;
if (!initialized) {
for (int i = 0; i < 256; i++) {
uint64 c = i;
for (int j = 0; j < 8; j++)
c = ((c & 1) ? CV_BIG_UINT(0xc96c5795d7870f42) : 0) ^ (c >> 1);
table[i] = c;
}
initialized = true;
}
uint64 crc = ~crcx;
for (size_t idx = 0; idx < size; idx++) {
crc = table[(uchar)crc ^ data[idx]] ^ (crc >> 8);
}
return ~crc;
}
bsearch & qsort
- https://www.tutorialspoint.com/c_standard_library/c_function_bsearch.htm
- https://www.tutorialspoint.com/c_standard_library/c_function_qsort.htm
int compare(const void* a, const void* b) {
return (*(int*)a - *(int*)b);
}
int cmpfunc(const void * a, const void * b) {
return ( *(int*)a - *(int*)b );
}
qsort(ali, size, sizeof(int), compare);
qsort(values, 5, sizeof(int), cmpfunc);
#include <stdio.h>
#include <stdlib.h>
int cmpfunc(const void * a, const void * b) {
return ( *(int*)a - *(int*)b );
}
int values[] = { 5, 20, 29, 32, 63 };
int main () {
int *item;
int key = 32;
/* using bsearch() to find value 32 in the array */
item = (int*) bsearch (&key, values, 5, sizeof (int), cmpfunc);
if ( item != NULL ) {
printf("Found item = %d\n", *item);
} else {
printf("Item = %d could not be found\n", *item);
}
return(0);
}
log C#
using System.IO;
using System.Diagnostics;
private static bool m_bLocalDebug = true;
public static void WriteLog(string strLog)
{
if (!m_bLocalDebug) {
return;
}
string sFilePath = "D:\\" + DateTime.Now.ToString("yyyyMM");
string sFileName = "logfile" + Process.GetCurrentProcess().Id +
"-" + DateTime.Now.ToString("dd") + ".log";
sFileName = sFilePath + "\\" + sFileName; // 文件的绝对路径
if (!Directory.Exists(sFilePath)) { // 验证路径是否存在
Directory.CreateDirectory(sFilePath);
}
FileStream fs;
bool create = false;
if (File.Exists(sFileName)) {
fs = new FileStream(sFileName, FileMode.Append, FileAccess.Write);
} else {
fs = new FileStream(sFileName, FileMode.Create, FileAccess.Write);
create = true;
}
StreamWriter sw = new StreamWriter(fs);
if (create) {
String commandLineString = System.Environment.CommandLine;
String[] args = System.Environment.GetCommandLineArgs();
sw.WriteLine(commandLineString);
for (int i = 0; i < args.Length; i++) {
sw.WriteLine(args[i]);
}
sw.WriteLine("--------");
}
sw.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH-mm-ss") + " --- " + strLog);
sw.Close();
fs.Close();
}
log C++
FILE *fp = NULL;
fp = fopen("D:\\camera.txt", "a");
if (fp)
{
fprintf(fp, "%s %d \n", __FILE__, __LINE__);
fclose(fp);
}
FILE* fp = NULL;
errno_t err = fopen_s(&fp, "E:\\irrlicht.txt", "a");
if (err == 0 && fp)
{
fprintf(fp, "%s@x\n", lpcstr);
fclose(fp);
}
char fpath[1024] = "";
_fullpath(fpath, fileLocation, 1024);
{ // C 版本。#include <locale>
setlocale(LC_ALL, "chs");
FILE* fp = NULL;
errno_t err = fopen_s(&fp, "E:\\curl.txt", "a");
if (err == 0 && fp) {
fwprintf(fp, L"%s\n", szUrl);
for (int i = 0; i < nSize; i++) {
fputc(pBuffer[i], fp);
}
fputc('\n', fp);
fclose(fp);
}
}
C++ File
- ‘r’ 读
- ‘w’ 写
- ‘a’ 追加
- ‘r+’ == r+w(读写,可读可写,文件若不存在就报错 IOError)
- ‘w+’ == w+r(写读,可读可写,文件若不存在就创建)
- ‘a+’ == a+r(可追加可写,文件若不存在就创建)
- 对应的,如果是二进制文件,需要加一个 b:
- ‘rb’ ‘wb’ ‘ab’ ‘rb+’ ‘wb+’ ‘ab+’
- 注意!‘w’会抹去文件原有的内容,如果只是加新的内容应该用‘a’
long getfileSize(const char* fpath) {
FILE* fs = fopen(fpath, "rb");
assert(fs);
if (!fs) return -1;
fseek(fs, 0, SEEK_END);
long length = ftell(fs);
// rewind(fs);
fclose(fs);
return length;
}
// FILE* file;
// if (fopen_s(&file, datfile.c_str(), "rb") == 0) {
// fobj = std::shared_ptr<FILE>(file, std::fclose);
// }
// else {
// assert(false);
// return;
// }
bool readfileSeek(const char* fpath, char* buffer, long readsize, long seek) {
FILE* fs = fopen(fpath, "rb");
assert(fs);
if (!fs) return false;
fseek(fs, seek, SEEK_SET);
fread(buffer, 1, readsize, fs);
fclose(fs);
return true;
}
char* readfile(const char* fpath, long& length) {
FILE* fs = fopen(fpath, "rb");
assert(fs);
if (!fs) return nullptr;
fseek(fs, 0, SEEK_END);
length = ftell(fs);
rewind(fs);
char* data = new char[length + 1];
fread(data, 1, length, fs);
data[length] = 0;
fclose(fs);
return data;
}
// 返回开始写文件的地址偏移。
long appendfile(const char* fpath, const char* data, long length) {
assert(data && length > 0);
if (!data || length <= 0) return -1;
FILE* fs = fopen(fpath, "ab");
assert(fs);
if (!fs) return -1;
fseek(fs, 0, SEEK_END);
long offset = ftell(fs);
fwrite(data, 1, length, fs);
fclose(fs);
return offset;
}
bool IsFileRegular(const std::string &path) {
struct stat st;
if (stat(path.c_str(), &st))
return false;
return S_ISREG(st.st_mode);
}
bool IsDirectory(const std::string &path)
{
struct stat st;
if (stat(path.c_str(), &st))
return false;
return S_ISDIR(st.st_mode);
}
// exdir 表示进行文件夹检查,不能是 文件夹。
bool IsFilePathExists(const char* path, bool exdir)
{
// 如果指定的存取方式有效,则函数返回 0,否则函数返回 -1。
int code = ::access(path, 0);
if (0 == code) {
if (exdir && IsDirectory(path)) {
return false;
}
return true;
}
return false;
}
#include "shlwapi.h"
#pragma comment(lib, "shlwapi.lib")
void myCreateDirectory(const wchar_t* fpath, bool isfile = true) {
std::wstring fdir = fpath;
if (!isfile) {
if (PathIsDirectory(fdir.c_str())) {
return;
}
}
int index = -1;
int temp = 0;
if ((temp = fdir.rfind(L"/")) != -1) {
index = std::max(index, temp);
}
if ((temp = fdir.rfind(L"\\")) != -1) {
index = std::max(index, temp);
}
if (index != -1) {
myCreateDirectory(fdir.substr(0, index).c_str(), false);
}
if (!isfile) {
::CreateDirectory(fdir.c_str(), NULL);
}
}
bool CreateDeepDirectory(const char* szPath)
{
if (IsDirectory(szPath)) {
return true;
}
if (IsFilePathExists(szPath, false))
return false;
#ifdef __ANDROID__
if (0 != ::mkdir(szPath, 0777))
#else
if (0 != ::mkdir(szPath))
#endif
{
StringDup strPath(szPath);
if (!PathRemoveFileName(strPath) || IsFilePathEmpty(strPath)) {
return false;
}
if (!CreateDeepDirectory(strPath))
return false;
#ifdef __ANDROID__
if (0 != ::mkdir(szPath, 0777))
#else
if (0 != ::mkdir(szPath))
#endif
return false;
}
return true;
}
std::string GetAbsolutePath(const std::string& filename)
{
if (filename.empty())
return filename;
#if defined(_WIN32)
char fpath[_MAX_PATH] = { 0 };
char* p = _fullpath(fpath, filename.c_str(), _MAX_PATH);
std::string tmp(p);
return tmp;
#else
char fpath[4096] = { 0 };
char* p = realpath(filename.c_str(), fpath);
std::string tmp(p);
return tmp;
#endif
}
C++ String
On Windows, wchar_t is UTF-16 while on other platform such as Linux and MacOS, wchar_t is UTF-32!
link
#include <string>
#include <sstream>
template<typename T>
inline std::string stringify(const T& x)
{
std::ostringstream o;
if (!(o << x)) return "";
return o.str();
}
template<typename T>
inline T fromString(char *s)
{
std::string str = s;
std::istringstream i(str);
T x;
i >> x;
return x;
}
#include <codecvt>
// C++17: codecvt_utf8 is deprecated
std::wstring convert_to_wstring(const std::string &str)
{
std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>, wchar_t> conv;
return conv.from_bytes(str);
}
std::string convert_from_wstring(const std::wstring &wstr)
{
std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>, wchar_t> conv;
return conv.to_bytes(wstr);
}
#include "stdafx.h"
#include <assert.h>
#include <string>
// C++17: codecvt_utf8 is deprecated
// std::wstring_convert<std::codecvt_utf8<wchar_t>> strConvert;
// 有的字符串可能会编码失败。
std::wstring CharToWChar(const char* str, size_t encode) {
if (!str)
return L"";
int srclen = strlen(str);
int len = MultiByteToWideChar(encode, 0, str, srclen, NULL, 0);
if (len <= 0) {
return L"";
}
wchar_t* temp = new wchar_t[len + 1];
MultiByteToWideChar(encode, 0, str, srclen, temp, len);
temp[len] = '\0';
std::wstring wstr = temp;
delete[] temp;
return wstr;
}
// 有的字符串可能会编码失败。
std::string WCharToChar(const wchar_t* wstr, size_t encode) {
if (!wstr)
return "";
int srclen = wcslen(wstr);
int len = WideCharToMultiByte(encode, 0, wstr, srclen, NULL, 0, NULL, NULL);
if (len <= 0) {
return "";
}
char* temp = new char[len + 1];
WideCharToMultiByte(encode, 0, wstr, srclen, temp, len, NULL, NULL);
temp[len] = '\0';
std::string str = temp;
delete[] temp;
return str;
}
std::string UTF8_ENCODE(const wchar_t* wstr) {
if (!wstr)
return "";
return WCharToChar(wstr, CP_UTF8);
}
std::wstring UTF8_DECODE(const char* str) {
if (!str)
return L"";
return CharToWChar(str, CP_UTF8);
}
字符串加解密
这个存在缺陷,如果转码失败会不可逆:
wchar_t bkHexWChar(const wchar_t* buffer, int cntlen = 4) {
wchar_t* num = new wchar_t[cntlen + 1];
memcpy(num, buffer, cntlen * sizeof(wchar_t));
num[cntlen] = 0;
wchar_t ch = wcstol(num, NULL, 16);
delete[] num;
return ch;
}
int bkHexChar(const char* buffer, int cntlen = 2) {
char* num = new char[cntlen + 1];
memcpy(num, buffer, cntlen * sizeof(char));
num[cntlen] = 0;
int ch = strtol(num, NULL, 16);
delete[] num;
return ch;
}
CString toHexString(CString str) {
std::string strk = WCharToChar(str.GetString());
const int length = strk.length();
const char* buffer = strk.c_str();
assert(length >= 0 && length <= 0xffff);
CString retv;
retv.AppendFormat(L"%04x", length);
for (int i = 0; i < length; i++) {
// 宽字符型 wchar_t (unsigned short.)
// wchar_t ch = buffer[i];
// assert(ch >= 0 && ch <= 0xffff);
unsigned char ch = buffer[i];
assert(ch >= 0 && ch <= 0xff);
retv.AppendFormat(L"%02x", ch);
}
return retv;
}
CString bkHexString(CString str) {
std::string strk = WCharToChar(str.GetString());
int srclen = strk.length();
assert((srclen - 4) % 2 == 0 && srclen >= 4);
if ((srclen - 4) % 2 != 0 || srclen < 4) {
return L"";
}
const char* buffer = strk.c_str();
const int length = bkHexChar(&buffer[0], 4);
assert(length == (srclen - 4) / 2);
if (length != (srclen - 4) / 2) {
return L"";
}
CStringA retv;
for (int i = 0; i < length; i++) {
char ch = bkHexChar(&buffer[4 + i * 2]);
retv.AppendChar(ch);
}
std::wstring temp = CharToWChar(retv.GetString());
CString wstr = temp.c_str();
return wstr;
}
int _tmain(int argc, _TCHAR* argv[])
{
CString test = L"中文 123";
test = toHexString(test);
test = bkHexString(test);
test = bkHexString(L"0004ffffff01");
test = toHexString(test);
return 0;
}
这个方案,加密字符串长一点,但是肯定没问题:
#include <assert.h>
#define ALG_TYPE 0x07
class b62 {
public:
static int ParseBase62(wchar_t ch) {
if (ch >= L'0' && ch <= L'9') {
return ch - L'0';
}
if (ch >= L'a' && ch <= L'z') {
return ch - L'a' + 10;
}
if (ch >= L'A' && ch <= L'Z') {
return ch - L'A' + 10 + 26;
}
return -1;
}
static int appendHex(CString& retv, unsigned long value) {
int len = 0;
for (unsigned long temp = value; len == 0 || temp; temp /= 62) {
len++;
}
static wchar_t SZ_BASE62_TAB[] =
L"0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
retv.AppendChar(SZ_BASE62_TAB[len]);
for (int i = 0; i < len; i++) {
int node = value % 62;
retv.AppendChar(SZ_BASE62_TAB[node]);
value /= 62;
}
return len;
}
static unsigned long eatupHex(const wchar_t* ptr, unsigned int& index) {
int len = ParseBase62(ptr[index++]);
unsigned long value = 0;
unsigned long mulval = 1;
for (int i = 0; i < len; i++) {
int node = ParseBase62(ptr[index++]);
value += node * mulval;
mulval *= 62;
}
return value;
}
static CString toHexString(CString str) {
const int length = str.GetLength();
const wchar_t* buffer = str.GetString();
CString retv;
appendHex(retv, ALG_TYPE);
appendHex(retv, length);
wchar_t check = 0;
for (int i = 0; i < length; i++) {
wchar_t ch = buffer[i]; // <= 0xffff
appendHex(retv, ch ^ ALG_TYPE);
check ^= ch;
}
appendHex(retv, check);
return retv;
}
static CString bkHexString(CString str) {
unsigned int index = 0;
const wchar_t* buffer = str.GetString();
const int algType = eatupHex(buffer, index);
if (algType != ALG_TYPE) {
return L"??<unknow type>";
}
CString retv;
wchar_t check = 0;
const int length = eatupHex(buffer, index);
for (int i = 0; i < length; i++) {
wchar_t ch = eatupHex(buffer, index) ^ ALG_TYPE;
retv.AppendChar(ch);
check ^= ch;
}
wchar_t checkz = eatupHex(buffer, index);
assert(checkz == check);
if (checkz != check) {
return L"??<check error>";
}
return retv;
}
}; // namespace b62
拍脑袋最终版本
Base64 编码是使用 64 个可打印 ASCII 字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成 ASCII 字符串,另有“=”符号用作后缀用途。 因为 Base64 算法是将 3 个字节原数据编码为 4 个字节新数据,所以 Base64 编码后的数据比原始数据略长,为原来的 4/3。
两个变种:
- 用于 URL 的改进 Base64 编码,它在末尾填充 '=' 号,并将标准 Base64 中的“+”和“/”分别改成了“-”和“_”。
- 用于正则表达式的改进 Base64 变种,它将“+”和“/”改成了“!”和“-”。
- 设计一种编码,编码出来只有 62 个字符,并且尽可能短,每个字符独立编码,支持按字符检索。
- 62 编码,采取 59(质数)进制,XYZ 作为扩展标记。最短能从 16 进制得长度缩短到原来的 3/4 长度。
- 16 进制一次编码 4 bit,59 进制一次大概编码 6 bit。
- <= 58: 直接解析
- >= 59: XYZ 打头扩展编码。
单独一篇文章,验证这个问题: 实现 62 个字符的 Base64 编码
/**
* 设计一种编码,编码出来只有 62 个字符,并且尽可能短,
* 每个字符独立编码,支持按字符检索。
* 62 编码,采取 59(质数)进制,XYZ 作为扩展标记。
* 最短能从 16 进制得长度缩短到原来的 3/4 长度。
* 16 进制一次编码 4 bit,59 进制一次大概编码 6 bit。
* <= 58: 直接解析
* >= 59: XYZ 打头扩展编码。
*/
0 0 0
3a 58 W
3b 59 X0
75 117 XW
76 118 Y00
e0e 3598 YWW
e0f 3599 Z000
33051 208977 ZWWW
33052 208978 Z00X0
65294 414356 ZWWXW
65295 414357 Z00Y00
ffffe 1048574 ZqbY53
fffff 1048575 ZrbY53
0 0 P12000
StringHelper
#pragma once
#include <string>
#include <sstream>
#include <vector>
#include <stdexcept>
#include <cctype>
#include <algorithm>
class StringHelper
{
public:
static std::wstring toLower(std::wstring source)
{
std::transform(source.begin(), source.end(), source.begin(), [](unsigned char c) {
return std::tolower(c); });
return source;
}
static std::wstring toUpper(std::wstring source)
{
std::transform(source.begin(), source.end(), source.begin(), [](unsigned char c) {
return std::toupper(c); });
return source;
}
static std::wstring trimStart(std::wstring source, const std::wstring &trimChars = L" \t\n\r\v\f")
{
return source.erase(0, source.find_first_not_of(trimChars));
}
static std::wstring trimEnd(std::wstring source, const std::wstring &trimChars = L" \t\n\r\v\f")
{
return source.erase(source.find_last_not_of(trimChars) + 1);
}
static std::wstring trim(std::wstring source, const std::wstring &trimChars = L" \t\n\r\v\f")
{
return trimStart(trimEnd(source, trimChars), trimChars);
}
static std::wstring replace(std::wstring source, const std::wstring &find, const std::wstring &replace)
{
std::size_t pos = 0;
while ((pos = source.find(find, pos)) != std::wstring::npos) {
source.replace(pos, find.length(), replace);
pos += replace.length();
}
return source;
}
static bool startsWith(const std::wstring &source, const std::wstring &value)
{
if (source.length() < value.length())
return false;
else
return source.compare(0, value.length(), value) == 0;
}
static bool endsWith(const std::wstring &source, const std::wstring &value)
{
if (source.length() < value.length())
return false;
else
return source.compare(source.length() - value.length(), value.length(), value) == 0;
}
static std::vector<std::wstring> split(const std::wstring &source, wchar_t delimiter)
{
std::vector<std::wstring> output;
std::wistringstream ss(source);
std::wstring nextItem;
while (std::getline(ss, nextItem, delimiter)) {
output.push_back(nextItem);
}
return output;
}
template<typename T>
static std::wstring toString(const T& subject)
{
std::wostringstream ss;
ss << subject;
return ss.str();
}
template<typename T>
static std::string toStringA(const T& subject)
{
std::ostringstream ss;
ss << subject;
return ss.str();
}
template<typename T>
static T fromString(const std::wstring &subject)
{
std::wistringstream ss(subject);
T target;
ss >> target;
return target;
}
template<typename T>
static T fromStringA(const std::string &subject)
{
std::istringstream ss(subject);
T target;
ss >> target;
return target;
}
static bool isEmptyOrWhiteSpace(const std::wstring &source)
{
if (source.length() == 0)
return true;
else {
for (std::size_t index = 0; index < source.length(); index++) {
if (!std::isspace(source[index]))
return false;
}
return true;
}
}
};
class StringHelper
{
public:
template<typename T>
static std::wstring formatSimple(const std::wstring &input, T arg)
{
std::wostringstream ss;
std::size_t lastCloseBrace = std::wstring::npos;
std::size_t openBrace = std::wstring::npos;
while ((openBrace = input.find(L'{', openBrace + 1)) != std::wstring::npos) {
if (openBrace + 1 < input.length()) {
if (input[openBrace + 1] == L'{') {
openBrace++;
continue;
}
std::size_t closeBrace = input.find(L'}', openBrace + 1);
if (closeBrace != std::wstring::npos) {
ss << input.substr(lastCloseBrace + 1, openBrace - lastCloseBrace - 1);
lastCloseBrace = closeBrace;
std::wstring index = trim(input.substr(openBrace + 1, closeBrace - openBrace - 1));
if (index == L"0")
ss << arg;
else
throw std::runtime_error(
"Only simple positional format specifiers are handled by the 'formatSimple' helper method.");
}
}
}
if (lastCloseBrace + 1 < input.length())
ss << input.substr(lastCloseBrace + 1);
return ss.str();
}
template<typename T>
static std::wstring formatSimple(const std::wstring &input, const std::vector<T> &args)
{
std::wostringstream ss;
std::size_t lastCloseBrace = std::wstring::npos;
std::size_t openBrace = std::wstring::npos;
while ((openBrace = input.find(L'{', openBrace + 1)) != std::wstring::npos) {
if (openBrace + 1 < input.length()) {
if (input[openBrace + 1] == L'{') {
openBrace++;
continue;
}
std::size_t closeBrace = input.find(L'}', openBrace + 1);
if (closeBrace != std::wstring::npos) {
ss << input.substr(lastCloseBrace + 1, openBrace - lastCloseBrace - 1);
lastCloseBrace = closeBrace;
std::wstring index = trim(input.substr(openBrace + 1, closeBrace - openBrace - 1));
ss << args[std::stoi(index)];
}
}
}
if (lastCloseBrace + 1 < input.length())
ss << input.substr(lastCloseBrace + 1);
return ss.str();
}
template<typename T1, typename T2>
static std::wstring formatSimple(const std::wstring &input, T1 arg1, T2 arg2)
{
std::wostringstream ss;
std::size_t lastCloseBrace = std::wstring::npos;
std::size_t openBrace = std::wstring::npos;
while ((openBrace = input.find(L'{', openBrace + 1)) != std::wstring::npos) {
if (openBrace + 1 < input.length()) {
if (input[openBrace + 1] == L'{') {
openBrace++;
continue;
}
std::size_t closeBrace = input.find(L'}', openBrace + 1);
if (closeBrace != std::wstring::npos) {
ss << input.substr(lastCloseBrace + 1, openBrace - lastCloseBrace - 1);
lastCloseBrace = closeBrace;
std::wstring index = trim(input.substr(openBrace + 1, closeBrace - openBrace - 1));
if (index == L"0")
ss << arg1;
else if (index == L"1")
ss << arg2;
else
throw std::runtime_error(
"Only simple positional format specifiers are handled by the 'formatSimple' helper method.");
}
}
}
if (lastCloseBrace + 1 < input.length())
ss << input.substr(lastCloseBrace + 1);
return ss.str();
}
template<typename T1, typename T2, typename T3>
static std::wstring formatSimple(const std::wstring &input, T1 arg1, T2 arg2, T3 arg3)
{
std::wostringstream ss;
std::size_t lastCloseBrace = std::wstring::npos;
std::size_t openBrace = std::wstring::npos;
while ((openBrace = input.find(L'{', openBrace + 1)) != std::wstring::npos) {
if (openBrace + 1 < input.length()) {
if (input[openBrace + 1] == L'{') {
openBrace++;
continue;
}
std::size_t closeBrace = input.find(L'}', openBrace + 1);
if (closeBrace != std::wstring::npos) {
ss << input.substr(lastCloseBrace + 1, openBrace - lastCloseBrace - 1);
lastCloseBrace = closeBrace;
std::wstring index = trim(input.substr(openBrace + 1, closeBrace - openBrace - 1));
if (index == L"0")
ss << arg1;
else if (index == L"1")
ss << arg2;
else if (index == L"2")
ss << arg3;
else
throw std::runtime_error(
"Only simple positional format specifiers are handled by the 'formatSimple' helper method.");
}
}
}
if (lastCloseBrace + 1 < input.length())
ss << input.substr(lastCloseBrace + 1);
return ss.str();
}
};
pystring
#ifndef INCLUDED_PYSTRING_H
#define INCLUDED_PYSTRING_H
#include <string>
#include <vector>
namespace pystring
{
#define MAX_32BIT_INT 2147483647
bool startswith( const std::string & str, const std::string & prefix, int start = 0, int end = MAX_32BIT_INT );
bool endswith( const std::string & str, const std::string & suffix, int start = 0, int end = MAX_32BIT_INT );
std::string strip( const std::string & str, const std::string & chars = "" );
std::string lstrip( const std::string & str, const std::string & chars = "" );
std::string rstrip( const std::string & str, const std::string & chars = "" );
std::string upper( const std::string & str );
std::string lower( const std::string & str );
std::string mul( const std::string & str, int n);
std::string join( const std::string & str, const std::vector< std::string > & seq );
void split( const std::string & str, std::vector< std::string > & result,
const std::string & sep = "", int maxsplit = -1);
void splitlines( const std::string & str, std::vector< std::string > & result, bool keepends = false );
std::string replace( const std::string & str, const std::string & oldstr,
const std::string & newstr, int count = -1);
bool isalnum( const std::string & str );
bool isalpha( const std::string & str );
bool isdigit( const std::string & str );
bool isspace( const std::string & str );
bool islower( const std::string & str );
bool isupper( const std::string & str );
namespace os
{
namespace path
{
std::string basename(const std::string & path);
std::string dirname(const std::string & path);
std::string abspath(const std::string & path, const std::string & cwd);
std::string join(const std::string & path1, const std::string & path2);
std::string join(const std::vector< std::string > & paths);
std::string normpath(const std::string & path);
void split(std::string & head, std::string & tail, const std::string & path);
} // namespace path
} // namespace os
} // namespace pystring
#endif
#include "pystring.h"
#include <algorithm>
#include <cctype>
#include <cstring>
#include <iostream>
#include <sstream>
namespace pystring
{
#if defined(_WIN32) || defined(_WIN64) || defined(_WINDOWS) || defined(_MSC_VER)
#ifndef WINDOWS
#define WINDOWS
#endif
#endif
typedef int Py_ssize_t;
const std::string forward_slash = "/";
const std::string double_forward_slash = "//";
const std::string triple_forward_slash = "///";
const std::string double_back_slash = "\\";
const std::string empty_string = "";
const std::string dot = ".";
const std::string double_dot = "..";
const std::string colon = ":";
#define ADJUST_INDICES(start, end, len) \
if (end > len) \
end = len; \
else if (end < 0) { \
end += len; \
if (end < 0) \
end = 0; \
} \
if (start < 0) { \
start += len; \
if (start < 0) \
start = 0; \
}
namespace {
void split_whitespace( const std::string & str,
std::vector< std::string > & result, int maxsplit )
{
std::string::size_type i, j, len = str.size();
for (i = j = 0; i < len; ) {
while ( i < len && ::isspace( str[i] ) ) i++;
j = i;
while ( i < len && ! ::isspace( str[i]) ) i++;
if (j < i) {
if ( maxsplit-- <= 0 ) break;
result.push_back( str.substr( j, i - j ));
while ( i < len && ::isspace( str[i])) i++;
j = i;
}
}
if (j < len) {
result.push_back( str.substr( j, len - j ));
}
}
} // anonymous namespace
void split( const std::string & str, std::vector< std::string > & result,
const std::string & sep, int maxsplit )
{
result.clear();
if ( maxsplit < 0 ) maxsplit = MAX_32BIT_INT;//result.max_size();
if ( sep.size() == 0 ) {
split_whitespace( str, result, maxsplit );
return;
}
std::string::size_type i,j, len = str.size(), n = sep.size();
i = j = 0;
while ( i+n <= len ) {
if ( str[i] == sep[0] && str.substr( i, n ) == sep ) {
if ( maxsplit-- <= 0 ) break;
result.push_back( str.substr( j, i - j ) );
i = j = i + n;
} else {
i++;
}
}
result.push_back( str.substr( j, len-j ) );
}
#define LEFTSTRIP 0
#define RIGHTSTRIP 1
#define BOTHSTRIP 2
std::string do_strip( const std::string & str, int striptype, const std::string & chars )
{
Py_ssize_t len = (Py_ssize_t) str.size(), i, j, charslen = (Py_ssize_t) chars.size();
if ( charslen == 0 ) {
i = 0;
if ( striptype != RIGHTSTRIP ) {
while ( i < len && ::isspace( str[i] ) ) {
i++;
}
}
j = len;
if ( striptype != LEFTSTRIP ) {
do {
j--;
} while (j >= i && ::isspace(str[j]));
j++;
}
} else {
const char * sep = chars.c_str();
i = 0;
if ( striptype != RIGHTSTRIP ) {
while ( i < len && memchr(sep, str[i], charslen) ) {
i++;
}
}
j = len;
if (striptype != LEFTSTRIP) {
do {
j--;
} while (j >= i && memchr(sep, str[j], charslen) );
j++;
}
}
if ( i == 0 && j == len ) {
return str;
} else {
return str.substr( i, j - i );
}
}
std::string strip( const std::string & str, const std::string & chars )
{
return do_strip( str, BOTHSTRIP, chars );
}
std::string lstrip( const std::string & str, const std::string & chars )
{
return do_strip( str, LEFTSTRIP, chars );
}
std::string rstrip( const std::string & str, const std::string & chars )
{
return do_strip( str, RIGHTSTRIP, chars );
}
std::string join( const std::string & str, const std::vector< std::string > & seq )
{
std::vector< std::string >::size_type seqlen = seq.size(), i;
if ( seqlen == 0 ) return empty_string;
if ( seqlen == 1 ) return seq[0];
std::string result( seq[0] );
for ( i = 1; i < seqlen; ++i ) {
result += str + seq[i];
}
return result;
}
namespace
{
/* Matches the end (direction >= 0) or start (direction < 0) of self
* against substr, using the start and end arguments. Returns
* -1 on error, 0 if not found and 1 if found.
*/
int _string_tailmatch(const std::string & self, const std::string & substr,
Py_ssize_t start, Py_ssize_t end,
int direction)
{
Py_ssize_t len = (Py_ssize_t) self.size();
Py_ssize_t slen = (Py_ssize_t) substr.size();
const char* sub = substr.c_str();
const char* str = self.c_str();
ADJUST_INDICES(start, end, len);
if (direction < 0) {
// startswith
if (start+slen > len)
return 0;
} else {
// endswith
if (end-start < slen || start > len)
return 0;
if (end-slen > start)
start = end - slen;
}
if (end-start >= slen)
return (!std::memcmp(str+start, sub, slen));
return 0;
}
}
bool endswith( const std::string & str, const std::string & suffix, int start, int end )
{
int result = _string_tailmatch(str, suffix,
(Py_ssize_t) start, (Py_ssize_t) end, +1);
//if (result == -1) // TODO: Error condition
return static_cast<bool>(result);
}
bool startswith( const std::string & str, const std::string & prefix, int start, int end )
{
int result = _string_tailmatch(str, prefix,
(Py_ssize_t) start, (Py_ssize_t) end, -1);
//if (result == -1) // TODO: Error condition
return static_cast<bool>(result);
}
bool isalnum( const std::string & str )
{
std::string::size_type len = str.size(), i;
if ( len == 0 ) return false;
if ( len == 1 ) {
return ::isalnum( str[0] );
}
for ( i = 0; i < len; ++i ) {
if ( !::isalnum( str[i] ) ) return false;
}
return true;
}
bool isalpha( const std::string & str )
{
std::string::size_type len = str.size(), i;
if ( len == 0 ) return false;
if ( len == 1 ) return ::isalpha( (int) str[0] );
for ( i = 0; i < len; ++i ) {
if ( !::isalpha( (int) str[i] ) ) return false;
}
return true;
}
bool isdigit( const std::string & str )
{
std::string::size_type len = str.size(), i;
if ( len == 0 ) return false;
if ( len == 1 ) return ::isdigit( str[0] );
for ( i = 0; i < len; ++i ) {
if ( ! ::isdigit( str[i] ) ) return false;
}
return true;
}
bool islower( const std::string & str )
{
std::string::size_type len = str.size(), i;
if ( len == 0 ) return false;
if ( len == 1 ) return ::islower( str[0] );
for ( i = 0; i < len; ++i ) {
if ( !::islower( str[i] ) ) return false;
}
return true;
}
bool isspace( const std::string & str )
{
std::string::size_type len = str.size(), i;
if ( len == 0 ) return false;
if ( len == 1 ) return ::isspace( str[0] );
for ( i = 0; i < len; ++i ) {
if ( !::isspace( str[i] ) ) return false;
}
return true;
}
bool isupper( const std::string & str )
{
std::string::size_type len = str.size(), i;
if ( len == 0 ) return false;
if ( len == 1 ) return ::isupper( str[0] );
for ( i = 0; i < len; ++i ) {
if ( !::isupper( str[i] ) ) return false;
}
return true;
}
std::string lower( const std::string & str )
{
std::string s( str );
std::string::size_type len = s.size(), i;
for ( i = 0; i < len; ++i ) {
if ( ::isupper( s[i] ) ) s[i] = (char) ::tolower( s[i] );
}
return s;
}
std::string upper( const std::string & str )
{
std::string s( str ) ;
std::string::size_type len = s.size(), i;
for ( i = 0; i < len; ++i ) {
if ( ::islower( s[i] ) ) s[i] = (char) ::toupper( s[i] );
}
return s;
}
std::string replace( const std::string & str, const std::string & oldstr,
const std::string & newstr, int count )
{
int sofar = 0;
int cursor = 0;
std::string s( str );
std::string::size_type oldlen = oldstr.size(), newlen = newstr.size();
cursor = find( s, oldstr, cursor );
while ( cursor != -1 && cursor <= (int)s.size() ) {
if ( count > -1 && sofar >= count ) {
break;
}
s.replace( cursor, oldlen, newstr );
cursor += (int) newlen;
if ( oldlen != 0) {
cursor = find( s, oldstr, cursor );
} else {
++cursor;
}
++sofar;
}
return s;
}
void splitlines( const std::string & str, std::vector< std::string > & result, bool keepends )
{
result.clear();
std::string::size_type len = str.size(), i, j, eol;
for (i = j = 0; i < len; ) {
while (i < len && str[i] != '\n' && str[i] != '\r') i++;
eol = i;
if (i < len) {
if (str[i] == '\r' && i + 1 < len && str[i+1] == '\n') {
i += 2;
} else {
i++;
}
if (keepends)
eol = i;
}
result.push_back( str.substr( j, eol - j ) );
j = i;
}
if (j < len) {
result.push_back( str.substr( j, len - j ) );
}
}
std::string mul( const std::string & str, int n )
{
// Early exits
if (n <= 0) return empty_string;
if (n == 1) return str;
std::ostringstream os;
for(int i=0; i<n; ++i) {
os << str;
}
return os.str();
}
} // namespace pystring
动态加载 dll
//#include "pch.h"
#include <assert.h>
#include <Windows.h>
#include <string>
#ifndef __FAST_IMAGE_LIB__
#define __FAST_IMAGE_LIB__
#ifdef FAST_IMAGE_DLL_EXPORT
#define DLLEXPORT __declspec(dllexport)
#else
#define DLLEXPORT //__declspec(dllimport)
#endif
#ifdef __cplusplus
extern "C" {
#endif
namespace fastimage {
#define FAST_IMAGE_VERSION_NOTESHRINK 2
#define FAST_IMAGE_VERSION FAST_IMAGE_VERSION_NOTESHRINK
__interface IFastImageInterface {
virtual int getFastImageVersion() = 0;
virtual int getMagicAdvancedBitmap(FastImage fimage, FastImage & result, bool clearBackgroud = true) = 0;
virtual void release() = 0;
virtual int getMagicAdvancedBitmap2(FastImage fimage, FastImage & result, bool clearBackgroud = true) = 0;
};
DLLEXPORT IFastImageInterface* CreateFastImageObject();
typedef IFastImageInterface* (*CreateFastImageObjectFunc)();
} // namespace fastimage
class fastimagedll : public fastimage::IFastImageInterface {
static std::wstring getCurrentPath() {
wchar_t fpath[MAX_PATH];
DWORD dwRet = GetModuleFileName(NULL, fpath, MAX_PATH);
std::wstring fdir = fpath;
int index = fdir.rfind('\\');
return fdir.substr(0, index + 1);
}
static HINSTANCE getLibrary(const TCHAR* libPath) {
std::wstring curdir = getCurrentPath();
std::wstring current = curdir;
current.append(libPath);
WCHAR lpBuffer[MAX_PATH];
GetCurrentDirectory(MAX_PATH, lpBuffer);
SetCurrentDirectory(curdir.c_str());
HINSTANCE hDLL = LoadLibrary(current.c_str());
SetCurrentDirectory(lpBuffer);
if (hDLL == nullptr) {
int err = GetLastError();
return nullptr;
}
return hDLL;
}
public:
virtual int getFastImageVersion() {
if (!m_interface) {
return -1;
}
return m_interface->getFastImageVersion();
}
virtual int getMagicAdvancedBitmap(fastimage::FastImage fimage, fastimage::FastImage& result,
bool clearBackgroud = true) {
if (!m_interface) {
return -1;
}
return m_interface->getMagicAdvancedBitmap(fimage, result, clearBackgroud);
}
virtual int getMagicAdvancedBitmap2(fastimage::FastImage fimage, fastimage::FastImage& result,
bool clearBackgroud = true) {
if (!m_interface) {
return -1;
}
if (m_interface->getFastImageVersion() < FAST_IMAGE_VERSION_NOTESHRINK) {
return -2;
}
return m_interface->getMagicAdvancedBitmap2(fimage, result, clearBackgroud);
}
virtual void release() override {
delete this;
}
fastimagedll() {
const wchar_t* libPath = L"fastimage.dll";
m_hDLL = getLibrary(libPath);
if (m_hDLL == nullptr) {
int err = GetLastError();
return;
}
fastimage::CreateFastImageObjectFunc fptr =
(fastimage::CreateFastImageObjectFunc)GetProcAddress(m_hDLL, "CreateFastImageObject");
if (fptr == nullptr) {
int err = GetLastError();
return;
}
m_interface = fptr();
}
virtual ~fastimagedll() {
if (!m_interface) {
return;
}
m_interface->release();
m_interface = nullptr;
// m_hDLL 不释放了。
}
private:
fastimage::IFastImageInterface* m_interface = nullptr;
HINSTANCE m_hDLL = nullptr;
}; // class fastimagedll
#ifdef __cplusplus
}
#endif
#endif
参考资料快照
- https://zhuanlan.zhihu.com/p/515098548
- https://learn.microsoft.com/zh-cn/cpp/cpp/destructors-cpp?view=msvc-170
- https://www.jianshu.com/p/f3612e78e926
- https://en.cppreference.com/w/cpp/filesystem
- https://oi-wiki.org/ds/rbtree/
- https://www.cnblogs.com/zjy4869/p/15501448.html
- https://cloud.tencent.com/developer/article/1703257
- https://www.jianshu.com/p/58b602f8b7d5
- https://zhuanlan.zhihu.com/p/81438938
- https://github.com/zchrissirhcz/awesome-ncnn/blob/master/FAQ.md
- https://github.com/DataXujing/Qt_NCNN_NanoDet
- https://gitlab.kitware.com/cmake/cmake/-/issues/22564
- https://gitlab.kitware.com/cmake/cmake/-/blob/v3.21.1/Source/cmAddLibraryCommand.cxx#L224-231
- https://gmplib.org/devel/bc_bin_uiui.c
- https://datatracker.ietf.org/doc/html/draft-valin-celt-codec-00
- https://gitlab.xiph.org/xnorpx/opus/-/blob/5a6912d46449cb77e799f6c18f31b3108c5b3780/celt/cwrs.c
- https://stackoverflow.com/questions/53414711/math-behind-gcc9-modulus-optimizations
- https://blog.csdn.net/xbcReal/article/details/76685853
- https://www.0xaa55.com/thread-16949-1-1.html
- https://cjting.me/2021/03/16/the-missing-div-instruction-part1/
- https://blog.csdn.net/nameofcsdn/article/details/125007289
- https://rgplantz.github.io/2021/11/04/Shift-to-divide-by-10.html
- https://www.cnblogs.com/william-cheung/p/4831085.html
- https://dumphex.github.io/2020/03/09/local-static-object/
- https://opensource.apple.com/source/libcppabi/libcppabi-14/src/cxa_guard.cxx
- https://wiki.osdev.org/C++
- https://blog.csdn.net/flyingscv/article/details/2029509
- https://blog.csdn.net/ce123_zhouwei/article/details/108562387
- https://developer.arm.com/documentation/dui0530/m/Migrating-from-ARM-Compiler-v5-05-to-v5-06/Compiler-changes-between-ARM-Compiler-v5-05-and-v5-06/–ldrex-and—strex-intrinsics-deprecated
- https://blog.csdn.net/u012294613/article/details/123183813
- https://developer.android.google.cn/studio/archive.html
- https://www.cnblogs.com/flowerslip/p/5934718.html
- https://blog.csdn.net/u011700339/article/details/89302321
- https://www.tutorialspoint.com/c_standard_library/c_function_bsearch.htm
- https://www.tutorialspoint.com/c_standard_library/c_function_qsort.htm
- https://codingtidbit.com/2020/02/09/c17-codecvt_utf8-is-deprecated/
- 编程与调试 -- Tiny Module, Tiny My Life (Windows) | 04 Apr 2023
- 编程与调试 -- Tiny Source Code, Tiny My Life | 14 Sep 2021
 .
.