编程与调试 -- Windows 编程知识点(文档整理)1/2 基础
Windows C++ 开发基础
头文件引用顺序建议
- 预编译头文件
- 本 cpp 对应的头文件
- C 系统头文件
- C++ 系统头文件
- 项目内部头文件
类
- 不要在 C++ 中的构造函数与析构函数中调用虚函数
- 只要用到了继承关系,面向接口编程的情况下,都需要虚析构函数。
/we4263'function' : member function does not override any base class virtual member function。-
/we4264'virtual_function' : no override available for virtual member function from base 'class'; function is hidden# Enable and treat as errors the following warnings to easily detect virtual function signature failures: # 'function' : member function does not override any base class virtual member function # 'virtual_function' : no override available for virtual member function from base 'class'; function is hidden target_compile_options(trinity-compile-option-interface INTERFACE /we4263 /we4264)
接口定义
- C++ 没有 interface 关键字,所以我们使用定义纯虚函数的 class 作为
- 接口中不能定义成员变量
- 需要定义一个虚析构函数或者用于释放当前实例对象的纯虚函数,二者必选其一
开发环境和调试入门
提升代码质量:性能监控工具
Visual Studio 2019 提供了非常强大的性能分析工具,可以方便对位 CPU、内存问题。 通过按 F5 在 Visual Studio 中开始调试时,默认情况下会出现“诊断工具”窗口。 要手动打开该窗口, 请选择“Debug” > “Windows” > “Show Diagnostic Tools(诊断工具)”。“诊断工具”窗口显示有关事件、进程内存和 CPU 使用情况的信息。
Visual Studio 编译选项
Manifest 清单文件
- 我们在开发应用程序时,一般会引入一些第三方库,通常情况下,我们是把这些第三方依赖文件放到应用程序所处目 录,这样应用程序启动时就能正确找到相关依赖文件。但当依赖文件比较多,我们希望对依赖的文件进行归类,放置 到不同的目录下以便管理,这个时候应用程序的 manifest 就派上用场了。
- 在介绍应用程序的 manifest 之前,需要了解一下并行程序集(Side-by-Side Assembly)。什么是并行程序集呢?并 行程序集是微软为了解决 DLL Hell 问题而提出的一种解决方案,它采用 manifest 文件扫描组件之间的依赖关系。其 工作原理如下图所求:
- 什么是 DLL Hell 问题,微软在未提出 Side-by-Side Assembly 之前,应用程序启动时按照一定的规则加载 DLL。通 常情况下,应用程序会采用动态链接方式共享一些操作系统提供的基础库文件,当 Windows 更新共享库且共享库不 能向后兼容时(DLL 自身并不能向后兼容,这种情况通常发生在 DLL 的内存布局发生了改变),那些依赖于老版本共享 库的应用程序就不能正常工作了。
- 为了解决这个问题,微软重写了 DLL 动态加载子系统,提出了并行程序集的解决方案,即允许多个版本的库共同存在, 应用程序通过 manifest 描述自身所依赖的文件,SxS Manager 再通过 manifest 按照一定的规则找到应用程序的依 赖文件,使应用程序正确工作。
以 HelloWorld.exe 为例,假设它依赖 MyMath.dll,而我们又希望 MyMath.dll 放到 math 子目录,目录结构如下:
/AppDir
|--- HelloWorld.exe
| |
|--- math
|--- math.manifest
|--- MyMath.dll
SxS Manager 加载顺序。Side-by-side searches the WinSxS folder.
\\<appdir>\<assemblyname>.DLL\\<appdir>\<assemblyname>.manifest\\<appdir>\<assemblyname>\<assemblyname>.DLL\\<appdir>\<assemblyname>\<assemblyname>.manifest

Windbg 快速入门:调试 Notepad
- 打开 windbg,通过 File -> Open Executable 调起 notepad.exe
- 命令:x notepad!main 查找 main 函数入口
- 命令:bu notepad!WinMain 设置断点
- 命令:g 运行到 WinMain,触发断点
- 命令:k 查看当前调用堆栈
- 命令:bu ntdll!ZwWriteFile 查看保存文件调用堆栈
- 命令:~ 查看线程
- 命令:~0s 切换到 0 线程,k 查看调用堆栈
反调试手段 IsDebuggerPresent
!analyze 命令。自动分析崩溃的详细信息,分析异常崩溃的 dump 文件,第一步就是要执行 !analyze -v 异常调用栈。
Windows 系统导论
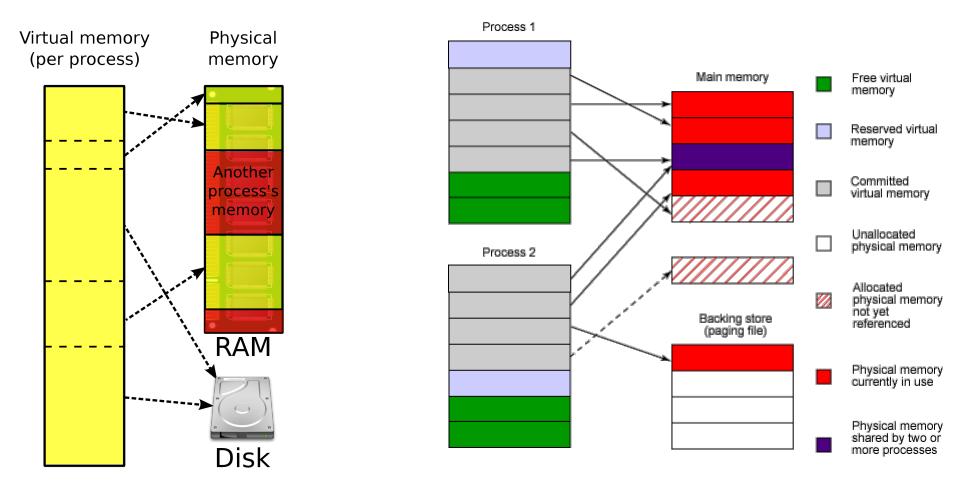
内存管理

虚拟地址转换

- MMU 和 TLB 都是硬件实现(减少操作系统的实现负担)
- TLB 是一个加速用的阔濴阔濻濸,命中时,目标内存都在物理内存中
栈空间
- ESP:栈指针寄存器 (extended stack pointer),该指针永远指向系统栈最上面一个栈帧的栈顶。
- EBP:基址指针寄存器 (extended base pointer),该指针永远指向系统栈最上面一个栈帧的底部。
- Callee 的第一个指令保存 caller 的 ebp。
TLS 线程本地存储
- 干啥用 线程范围内的全局存储
- 静态 编译器辅助:__declspec(thread) int number;
- 动态 通过 API 访问:TlsGetValue
Sleep vs Yield
- 等待其他线程的结果不要用 Sleep+Loop
- 正确的等待是用 WaitForSingleObject,WaitForMultiObjects 的 API
- 正确的让出时间片是:SwitchToThread
- WaitXxx 还有马上检查的功能
Windows 提供的同步对象
| 同步对象 | 支持等超时 | 进程锁 | 递归锁 | |
|---|---|---|---|---|
| CriticalSection 临界区 | 否 | 否 | 是 | 同一个进程内,实现互斥。 |
| Mutex 互斥量 | 是 | 是 | 是 | 可以跨进程,实现互斥。 |
| Event 事件 | 是 | 是 | N/A | 实现同步,可以跨进程。 |
| Semaphore 信号量 | 是 | 是 | N/A | 可用资源计数的功能 |
- 临界区:通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
- 临界区不是 OS 核心对象,如果进入理解去的线程“挂”了,将无法释放临界资源,这个缺点在互斥量中得到了弥补,因为使用互斥量可以设置超时值。
- 如果在 Critical Sections 中间突然程序 crash 或是 exit 而没有调用 LeaveCriticalSection,则结果是该线程所对应的内核不能被释放,该线程成为死线程。
- 互斥量: 一次只能由一个线程拥有,使线程能够协调对共享资源的互斥访问。 为协调共同对一个共享资源的单独访问而设计的。
- Mutex Can be owned by only one thread at a time, enabling threads to coordinate mutually exclusive access to a shared resource.
- 互斥对象包含一个使用数量,一个线程 ID 和一个递归计数器。
- 信号量: 维护介于零和一些最大值之间的计数,限制同时访问共享资源的线程数。 为控制一个具有有限数量用户资源而设计。信号允许多个线程同时使用共享资源。
- Semaphore Maintains a count between zero and some maximum value, limiting the number of threads that are simultaneously accessing a shared resource.
- CreateSemaphore()
- OpenSemaphore()
- ReleaseSemaphore()
- WaitForSingleObject()
- WaitForMultipleObjects()
- 事件: 通知一个或多个正在等待的线程已发生事件。 用来通知线程有一些事件已发生,从而启动后继任务的开始。
- Event Notifies one or more waiting threads that an event has occurred.
- Microsoft 没有为人工重置的事件定义成功等待的副作用,所以需要调用 ResetEvent()。
- Waitable Timer
- Waitable timer Notifies one or more waiting threads that a specified time has arrived.
其他
- 线程局部存储(TLS),同一进程中的所有线程共享相同的虚拟地址空间。
不同的线程中的局部变量有不同的副本,但是 static 和 globl 变量是同一进程中的所有线程共享的。
- 使用 TLS 技术可以为 static 和 globl 的变量,根据当前进程的线程数量创建一个 array,
- 每个线程可以通过 array 的 index 来访问对应的变量,这样也就保证了 static 和 global 的变量为每一个线程都创建不同的副本。
- 互锁函数的家族十分的庞大,例如 InterlockedExchangeAdd(),使用互锁函数的优点是:他的速度要比其他的 CriticalSection, Mutex, Event, Semaphore 快很多。
- 等待函数,例如 WaitForSingleObject 函数用来检测 hHandle 事件的信号状态,当函数的执行时间超过 dwMilliseconds 就返回,但如果参数 dwMilliseconds 为 INFINITE 时函数将直到相应时间事件变成有信号状态才返回,否则就一直等待下去,直到 WaitForSingleObject 有返回直才执行后面的代码。
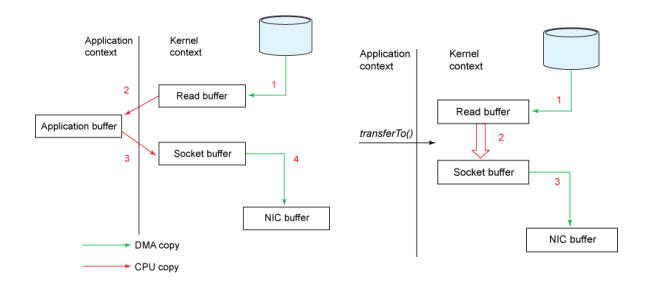
Zero Copy
- Linux 上的:sendfile
- Windows 上的:TransmitFile
x86 架构的包袱
- 复杂指令集 vs 精简指令集
- 思想差异:复杂问题是交给编译器,还是 CPU
- 指令不定长的问题
- 我们的视角:反编译;
- CPU 的视角:译码器效率、乱序执行效率
Windows 注册表
- 本质上是一个有权限管理功能的 key value 存储
- 在文件系统未初始化的时候就可以读取
- 存储系统的配置(驱动项、服务项、COM、文件类型…)
- 注册表是多 hives 的集合
对操作系统
- 相当于 grub3 中 ext3
- Bootmgr 在进系统前不需要文件系统支持
- 相当于给 kernel 使用的 ramfs
- Boot 类型的驱动在文件系统驱动加载前就可以读取到自己需要的配置
对应用程序
- 一个 KV 数据库
COM 组件

COM 组件
编程避坑不完全指引
- 多线程竞争问题(Cache、死锁等)
- 避免长时间高占用 CPU
- 需要频繁分配释放内存时使用内存池
- 注意内存映射的使用
- 避免对象(Handle)泄露,线程用完后揿毁
- 避免栈溢出(递归 vs 循环)
- Windows 上 xxx_s 函数
- 跨平台要考虑什么?(汇编、字节顺序,API 抽象)
- Wow64 的注册表、文件路径、Shell 扩展等
- 同一模块分配的内存、在同一模块内释放
- 尽可能顺序读写,避免大量随机读写
- 避免长时间高吞吐读写磁盘
- 少用黑魔法 (Undocumented API)
- 频繁的小任务可以用线程池管理
- 造轮子前要想清楚
- 不要在界面线程做和界面非相关的操作
Windows 界面和窗口
- WTL: Windows Template Library
Windows Template Library,对 ATL 在窗口方面做相关扩展。它封装好多 Windows 控件,也做了很多扩展。
- 标准控制(编辑框,列表框,按钮等等)
- 公共控制(包括列表视图,树形视图,进度条,微调按钮)
- IE 控制(rebar,平面滚动条,日历等等)
- 命令条,菜单,和更新 UI 类
- 公共对话框
- 属性单和页类
- 框架窗口,MDI 框架和子框架,分隔条,可滚动的窗口
- 设备环境(DC)和 GDI 对象类(笔、刷子、位图等)
- 打印机及其信息和设备模式类
- 实用工具类:包括 CPoint, CRect, CSize, 和 CString 类
-
ATL: Active Template Library(活动模板库) ATL 是 ActiveX Template Library 的缩写,它是一套 C++ 模板库。 ATL 是一个产生 C++/COM 代码的框架,就如同 C 语言是一个产生汇编代码的框架。
- STL 即 Standard Template Library(标准模板库) STL 的代码从广义上讲分为三类:algorithm(算法)、container(容器)和 iterator(迭代器)。 STL 是一些“容器”的集合,这些“容器”有 list, vector, set, map 等,STL 也是算法和其他一些组件的集合。 就像放在蛋架上的鸡蛋不会滚到桌上,它们很安全,因此,在 STL 容器中的对象也很安全。
GDI 绘制系统与动画
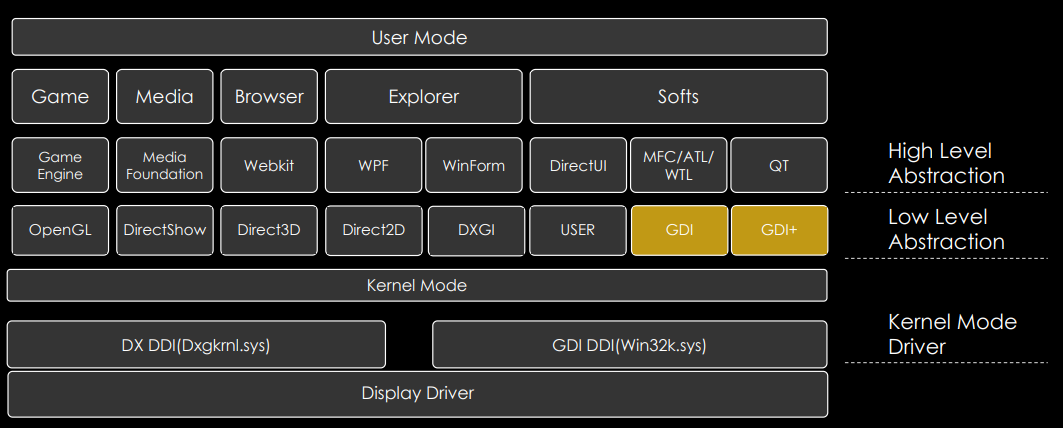
WINDOWS GRAPHICS ARCHITECTURE
GDI 对象的上限
There is a theoretical limit of 65,536 GDI handles per session.
However, the maximum number of GDI handles that can be opened per session is usually lower, since it is affected by available memory.
There is also a default per-process limit of GDI handles.
To change this limit, set the following registry value: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsNT\CurrentVersion\Windows\GDIProc essHandleQuota This value can be set to a number between 256 and 65,536.
句柄泄露
所有的 GDI 对象,在使用完成后,都需要调用删除,否则就会出现泄露问题 DeleteObject、ReleaseDC
GDI 的继任者:GDI+
GDI+ is an API that is exposed through a set of C++ classes. programmers of new applications should use GDI+ for all their graphics needs because GDI+ optimizes many of the capabilities of GDI and also provides additional features.
GETTING STARTED
#include <gdiplus.h>
using namespace Gdiplus;
#pragma comment(lib, "Gdiplus.lib")
INT WINAPI WinMain(HINSTANCE hInstance, HINSTANCE, PSTR, INT iCmdShow)
{
// Initialize GDI+.
GdiplusStartupInput gdiplusStartupInput;
ULONG_PTR gdiplusToken;
GdiplusStartup(&gdiplusToken, &gdiplusStartupInput, NULL);
// working with GDI+.
// Shutdown GDI+
GdiplusShutdown(gdiplusToken);
}
WHAT’S NEWS
- Gradient Brushes(渐变笔刷)
- Cardinal Splines(曲线拟合)
- Independent Path Objects(Path 对象的生命周期延长)
- Transformations and the Matrix Object(矩阵变换,旋转、缩放、平移)
- Scalable Regions(区域也可以进行缩放变换了)
- Alpha Blending(颜色混合)
- Support for Multiple Image Formats(图片格式支持:BMP\PNG\JPEG\ICON\GIF…)
模块和 COM 组件
DllMain
函数调用过程中有 ldr 锁,建议尽量不要做逻辑。 下面逻辑会触发 ldr 锁,确认不能在 dllmain 里面做以下事情:
- 调用 LoadLibrary(Ex)
- 使用 CoInitializeEx
- 使用 CreateProcess
- 使用 User32 或 Gdi32 中的函数
- 与其他线程同步执行
- 注意以上行为,间接调用也会引起,所以谨慎起见,尽量不用任何封装好的代码,除非你非常确认代码不会触发任何 ldr 锁。
原生 com 四个导出函数
- DllCanUnloadNow // 判断 dll 是否可以释放(引用计数是否为 0)
- DllGetClassObject // 获取接口类指针
- DllRegisterServer // 写注册表,注册为 com 组件,供任何人使用
- DllUnregisterServer // 删注册表,反注册
字符串编码和操作
- ASCII 美国信息交换标准代码
- 7 bit 表示一个字符
- 共 128 个字符
- ISO-8859-1 对于 ASCII 的扩展
- 8 bit 表示一个字符,会使用整个 byte
- 共 256 个字符
- GB2312 国标,汉字的编码集
- 2 byte 表示一个字符
- 共 6763 个汉字
- GBK 对于 GB2312 的扩展,能表示更多的字符
- 2 byte 表示一个字符
- 共 21003 个汉字
- GB18030 对于 GBK 的扩展,最完整的汉字编码集
- 变长多字节编码,1 个、2 个或 4 个 byte 表示一个字符
- 共 70000 余个汉字
- BIG5 由台湾制定,主要用于繁体汉字编码
- 2 byte 表示一个字符
- 共 13060 个汉字
- Unicode 由国际标准化组织制定,整合全世界的字符
- 2 byte 表示一个字符
- 表示全世界所有的字符
- 如果只使用英文字符,较浪费空间
- UTF(Unicode Translation Format) 通用转换格式,是 Unicode 的实现,解决了 Unicode 空间浪费的问题
- UTF-8, UTF-16, UTF-16LE(little endian), UTF-16BE(big endian), UTF-32
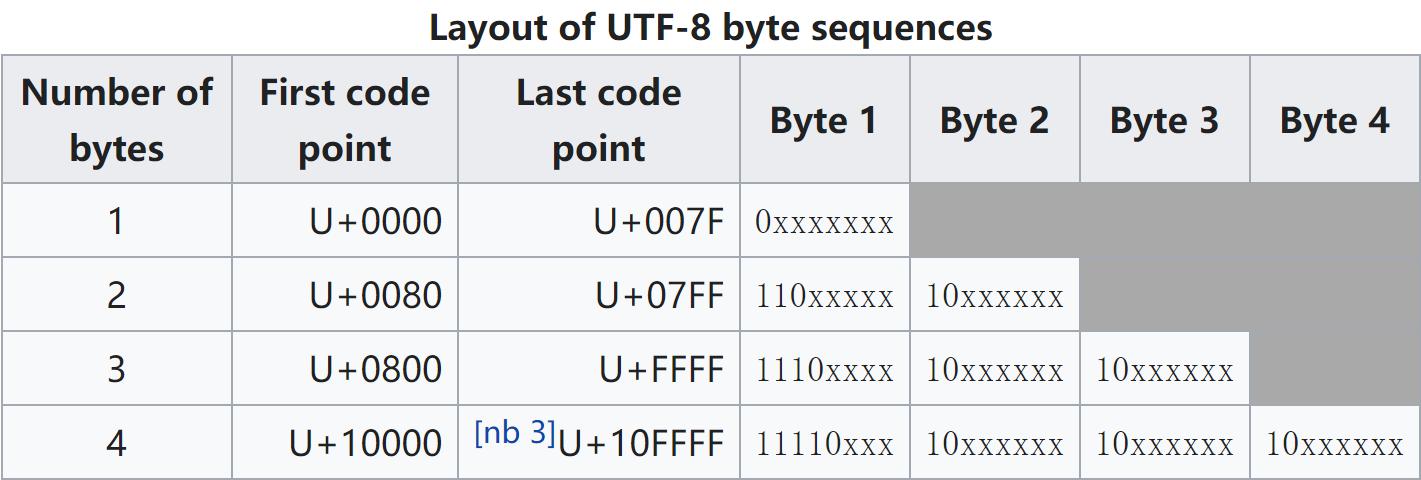
- UTF-8 变长多字节编码,1~4 字节表示一个字符
- 1 byte 表示一个 US-ASCIl 字符
- 2 byte 表示一个拉丁文字符(拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等)
- 3 byte 表示一个汉字(中日韩文字、东南亚文字、中东文字等)
- 4 byte 表示其他极少使用的语言
- UTF-8-BOM(Byte Order Mark)
- Unicode 规定使用 BOM 来标识字节顺序,UTF-8-BOM 的文件会以 EF BB BF 开头
- UTF-16 和 UTF-32 需要决定是按 2Byte 读还是按 4byte 读,需要 BOM 来决定顺序
- UTF-8 是按 1byte 读的,没有字节序问题,是不需要 BOM 来标识字节序的
- 建议:使用 UTF-8 时,最好使用不带 BOM 的 UTF-8
字符集 vs 字符编码
- 字符集:字符的集合,是集合就有范围
- GB2312:汉字 6763 个和非汉字图形字符 682 个,一些罕用字不在这个集合内
- GBK:包含 GB2312,GBK 编码是兼容 ASCII 编码的。
- GB18030:包含 GBK,2000 年和 2005 年,国家新增四字节的编码。
- 怎么编码:
- 纯 ascii 很好办,一个字符一个 byte
- 汉字怎么办?
- 编码方式
- 固定长度编码:不管英文字符还是中文字符,每个字符固定长度。长度太短,能编码的字符集越小,长度太长会造成浪费。
- 混合长度编码:ascii 字符一个字节,中文 2 or 3 个字节。简体中文的 Windows 系统默认就是这种编码方式。MBCS
- 问题:大部分情况下 OK,偶尔会遇到奇怪的路径。
- 科学的变长编码:UTF-8

BOOL IsUTF8(const char* _s, BOOL* is_ascii, char** invalid_point, int max_len)
{
const u_char* s = (const u_char*)_s;
const u_char* sv_s = s;
char* _invalid_point;
BOOL tmp;
if (!is_ascii) {
is_ascii = &tmp;
}
if (!invalid_point) {
invalid_point = &_invalid_point;
}
*is_ascii = TRUE;
while (*s && max_len-- > 0) {
if (*s >= 0x80) {
*is_ascii = FALSE;
*invalid_point = (char*)s;
if (*s <= 0xdf) {
if (--max_len <= 0 || (*++s & 0xc0) != 0x80) return FALSE;
}
else if (*s <= 0xef) {
if (--max_len <= 0 || (*++s & 0xc0) != 0x80) return FALSE;
if (--max_len <= 0 || (*++s & 0xc0) != 0x80) return FALSE;
}
else if (*s <= 0xf7) {
if (--max_len <= 0 || (*++s & 0xc0) != 0x80) return FALSE;
if (--max_len <= 0 || (*++s & 0xc0) != 0x80) return FALSE;
if (--max_len <= 0 || (*++s & 0xc0) != 0x80) return FALSE;
}
else return FALSE;
}
s++;
}
*invalid_point = NULL;
return TRUE;
}
BOOL StrictUTF8(char* s)
{
char* invalid_point = NULL;
if (!IsUTF8(s, NULL, &invalid_point) && invalid_point) {
*invalid_point = 0;
return TRUE;
}
return FALSE;
}
int U8Len(const char* s, int max_size)
{
if (max_size == -1) {
max_size = INT_MAX;
}
if (max_size == 0) {
return 0;
}
const char* sv_s = s;
int len;
int cur_size = 0;
for (len = 0; *s; len++) {
if (*s <= 0x7f) {
if ((cur_size += 1) > max_size) break;
}
else if (*s <= 0xdf) {
if ((cur_size += 2) > max_size) break;
if ((*++s & 0xc0) != 0x80) return -1;
}
else if (*s <= 0xef) {
if ((cur_size += 3) > max_size) break;
if ((*++s & 0xc0) != 0x80) return -1;
if ((*++s & 0xc0) != 0x80) return -1;
}
else if (*s <= 0xf7) {
if ((cur_size += 4) > max_size) break;
if ((*++s & 0xc0) != 0x80) return -1;
if ((*++s & 0xc0) != 0x80) return -1;
if ((*++s & 0xc0) != 0x80) return -1;
}
else return -1;
}
return len;
}
int u8cpyz(char* d, const char* s, int max_len)
{
int len = strncpyz(d, s, max_len);
if (StrictUTF8(d)) {
return (int)strlen(d);
}
return len;
}
/*
nul 文字を必ず付与する strncpy かつ return は 0 を除くコピー文字数
*/
int strncpyz(char* dest, const char* src, int num)
{
char* sv_dest = dest;
if (num <= 0) return 0;
while (--num > 0 && *src) {
*dest++ = *src++;
}
*dest = 0;
return (int)(dest - sv_dest);
}
ASCII /ˈæskiː/
(American Standard Code for Information Interchange) 编码起源于电报码,1960 年 10 月 6 日,美国标准协会(ANSI)的 X3.2 小组委员 会举行第一次会议,开始了关于 ASCII 标准制定。第一版 ASCII 标准于 1963 年发 布,在 1967 年经历了重大修改,在 1986 年期间经历了最近一次更新。ASCII 开始 基于英语字母表,将指定的 128 个字符编码成 7 位的二进制整数。其中 95 个编码 字符是可以打印的,包括数字 0-9,小写字母 a-z,大写字母 A-Z,还有一些标点 符号。
ISO-8859-1
ISO-8859-1 编码是单字节编码(8bit),向下兼容 ASCII,其编码范围是 0x00-0xFF,0x00-0x7F 之间完全和 ASCII 一致,0x80-0x9F 之间未定义, 0xA0-0xFF 之间主要是拉丁字母和符号。 此字符集广泛应用于欧洲地区国家,支持英语、丹麦、德语、西班牙语、 法语、冰岛语等。Windows 补全该编码中的未使用字符,形成自己的编码 Windows-1252(code page 1252)
Unicode
Unicode 是一种计算机行业统一编码标准,其起源是为了解决各国编码之 间的不兼容问题,创始人之一 Joe Becker 说为其取名‘Unicode’是为了表 明这是一种唯一的 (unique),统一的 (unified),通用的 (universal ) 编码。 Unicode 最初设计使用 16 位二进制来表示所有语言中的字符,因为当时所 有报纸和杂志的现代文字总和小于 2^14 = 16,384 。1991 年 3 月,Unicode 联 盟在加利福尼亚成立,10 月,发布 Unicode 1.0。
Unicode 的发展
- 1996 年发布 Unicode 2.0,加入了代理 字符机制 (Surrogate Characters Mechanism),将码域增加到了 100 多万, Unicode 不在局限于 16 位。
- 2000 年以后,Unicode 基本保持一年一 更的节奏,截止到 2020 年最新发布的 Unicode 10.0,已经拥有 143,859 个字 符。
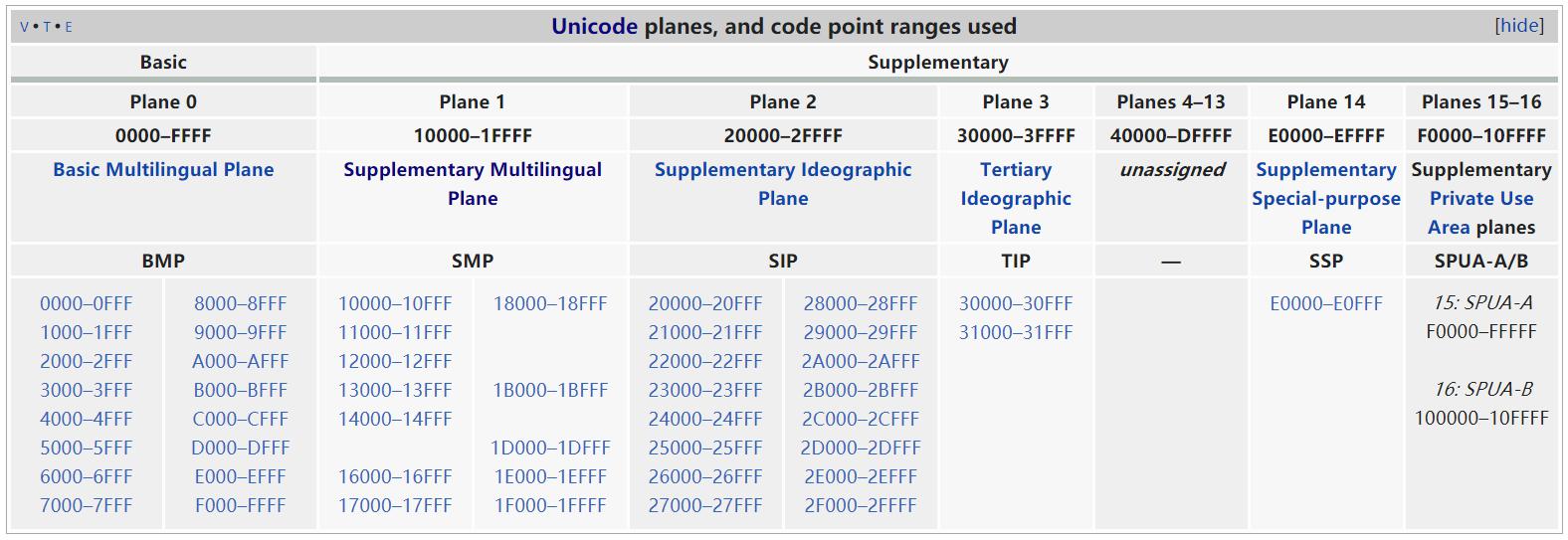
码域划分(Unicode 平面)

代理字符机制
编码方法
Unicode 定义了两种类型的编码方法:Unicode Transformation Format (UTF) 和 Universal Coded Character Set (UCS)
- UTF 编码有 UTF-8、UTF-16、UTF-32
- UCS 编码有 UCS-2,UCS-4
- Windows 上的 ANSI 编码
UTF-16
UTF-16(16-bit Unicode Transformation Format),是一种可变长编码,用 1 或 2 个 16 位(2 字节)代码单元进行编码。UTF-16 是从早期的 16 位定长编 码 UCS-2 发展而来,由于 16 位最多只能编码 65,536 个字符,随着需要使用的 字符越来越多,这明显不够用。于是 IEEE(Institute of Electrical and Electronics Engineers,电气与电子工程师协会)提出了 UCS-4 方案,用 4 字 节编码一个字符。Unicode 联盟觉得这个方案扯淡,因为这会浪费很多磁 盘空间,而且很多厂商已经投入大量资源基于 2 字节进行技术开发。最终 UTF-16 作为一个折中方案在 Unicode 2.0 标准中发布。
BMP:
- U+0000~U+D7FF 和 U+E000~U+FFFF(中间刚好缺少了 U+D800~U+DFFF,用于“代理字符机制”)
- 2 字节编码一个码点,直接前面补 0 即可。
SP:
- U+10000~U+10FFFF
- 码点个数:0x100000
假设 Unicode 码点 U,范围是(U+10000 ~ U+10FFFF)
- U 减去 0x10000 得到 range:0x00000 ~ 0xFFFFF
- 0xFFFFF 拆成两半 0x3ff & 0x3ff
- 分别加上“代理字符机制”,就是 高位:0xD800 ~ 0xDBFF,低位:0xDC00 ~ 0xDFFF

Unicode 字符:U+10437
先减去 0x10000,结果为 0x0437,转成 20 位二进制:0000000001 0000110111
高位:0x0001 + 0xD800 = 0xD801
低位:0x0037 + 0xDC00 = 0xDC37
所以 UTF-16 编码为:0xD801DC37
UTF-16 的一个代码单元是 2 字节,由于大多数通信协议和存储协议都是以字 节单位,于是在存储 UTF-16 序列的时候就需要选择字节序。为了便于识别 字节序,UTF-16 引入了 BOM(Byte Order Mark),插入在第一个实际代码 值之前。U+FEFF(零宽度不间断空格,啥也不是)表示大端,U+FFFE(非 字符)表示小端。UTF-16 规定如果缺少 BOM 头,应假设字节序为大端。
但事实上,因为 windows 默认使用小端,所以很多软件也默认使用小端, 平台的力量还是大。
特点:
- 可变长编码
- 不兼容 ASCII 编码
- 不可编码代理位
BOM (Byte Order Mark)
| UTF-8 | 0xEF 0xBB 0xBF |
| UTF-16 BE | 0xFE 0xFF |
| UTF-16 LE | 0xFF 0xFE |
| UTF-32 BE | 0x00 0x00 0xFE 0xFF |
| UTF-32 LE | 0xFF 0xFE 0x00 0x00 |
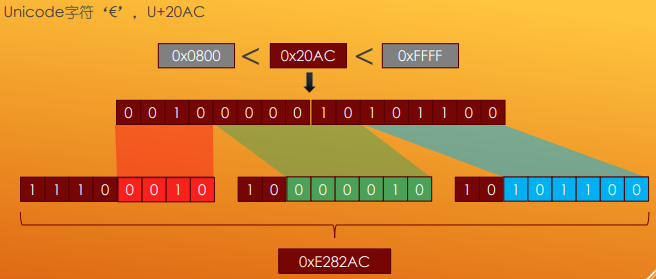
UTF-8
UTF-8 是一种可变长编码,使用 1-4 字节(8 位)编码所有 Unidcode 字符。与 ASCII 兼容,Unicode 前 128 个字符与 ASCII 是一一对应的,UTF-8 使用一字 节对其进行编码,并且在二进制值上与 ASCII 一样。UTF-8 已经成为了万维 网上的主导编码,截止到 2020 年,95% 网页使用 UTF-8 编码。IMC 推荐所有 的 e-mail 程序使用 UTF-8 展示和创建邮件,W3C 推荐将 UTF-8 作为 XML 和 HTML 的默认编码。

编码方式
UTF-8 编码的最小代码值单元是 1 字节,所以不存在字节序问题。但是很多 Windows 程序(Windows 记事本)会在以 UTF-8 保存的文件最前加上 0xEF, 0xBB, 0xBF,这个通常称为 BOM 头。
优势:
- 兼容 ASCII
- 字符边界容易识别
- 小于 U+0080 的编码只需一个字节
- 不用考虑字节序问题
- 相比 UTF-16 容错性更强
劣势:
- 编码 U+0800-U+FFFF 需要 3 字节
ANSI
ANSI 编码没有明确定义,但通常被用来指代 Windows 代码页(Windows code page),在英文系统上通常指 Windows-1252 代码页,在简体中文系统通常 指 Windows-936(在不同的 windows 系统上,可能指代不同的代码页)。事实上, “ANSI 编码”这个名字是个错误用法,应为 ANSI 从来没有发表过这样的标准。
Windows-1252 : 别名 CP-1252,用一个字节,总共编码 256 个字符,在英文和一些西方的 Windows 系统上作为默认编码。
Windows-936 : 别名 CP-936,是 Windows 系统为简体中文设计的编码,最初只覆盖 GB2312 中 的字符,但是随着 Window95 的发布,被扩展到覆盖大部分的 GBK。

更改默认 Code Page
Windows-936
第一部分:使用 1 个字节编码,0x00-0x80 和 0xff。总共编码 130 个字符, 前 128 个字符和 ASCII 兼容。
第二部分:使用 2 个字节编码,一个 lead byte(首字节),一个 trail byte(尾字节),lead byte 范围:0x81-0xfe(125),trail byte 范围: 0x40-0xfe(190),总共编码字符:23750
GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。总计 23940 个码位,共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。 from
同一个编码文件里,怎么区分 ASCII 和中文编码呢?从 ASCII 表我们知道标准 ASCII 只有 128 个字符,0~127 即 0x00~0x7F(0111 1111)。
所以区分的方法就是,高字节的最高位为 0 则为 ASCII,为 1 则为中文。from 
gbk 和 utf8 都是单字节编码,所以 strcpy 这种以 0(null)作为结束符的程序逻辑都是没问题的。 标准 ASCII 是 128 个,范围是 0x00~0x7F (0000 0000~0111 0000) ,最高位为 0。最高位为 1 作为扩展。
编码转换
MultiByteToWideChar // UTF-16 转 UTF-8 或者 ANSI
WideCharToMultiByte // UTF-16 转 UTF-8 或者 ANSI
CA2W // MultiByteToWideChar
CW2A // WideCharToMultiByte
CStringA sa;
CString s = sa; // 危险(ANSI)
#include <iostream>
#include <atlconv.h>
#include <atlstr.h>
int test() {
// 舒服,内存在堆上。默认:CP_THREAD_ACP,可以指定编码。
// 大字符串内存申请在 AtlConvAllocMemory 堆上。
std::string test3 = std::string(ATL::CW2A(L"中文字符", CP_UTF8));
std::wstring test4 = std::wstring(ATL::CA2W("中文字符"));
return 0;
}
int main()
{
USES_CONVERSION; // 使用 CP_THREAD_ACP
// 危险:使用了 alloca,这个内存申请在栈上。
std::string test1 = W2A(L"我是宽字节"); // 转化成默认
std::wstring test2 = A2W("我是窄字节"); // 危险,这玩意在栈上。
return 0;
}
将使用标准 C 的 mbstowcs 方法和 wcstombs 方法,且配合标准 C 的 setlocale 方法,这也是利用标准库跨平台的做法, 但是过程没法直接转成自定义的编码,需要额外转码。所以在 Windows 平台开发的话不推荐。 iconv
再谈字符集
- WideCharToMultiByte,将 Unicode 转换为多字节。其中入参:codePage,指定的是 Unicode 转换为目标字符串需要使用的编码映射表。(决定了输出字符串的编码方式)
- MultiByteToWideChar,将多字节转换为 Unicode。其中入参:codePage,指定的是源字符串转换为 Unicode 需要使用的编码映射表。(决定了输入字符串的编码方式)
- codePage,就是各种编码到 Unicode 的映射表。有几种典型的:
- CP_ACP,系统默认的代码页,在中文系统中一般为 GBK。在英文系统中为 ANSI。
- CP_THREAD_ACP,线程的代码页,在中文系统中一般为 GBK。在英文系统中为 ANSI。
- 936 —简体中文(GBK)
- UTF-8

这个设置影响的是 CP_ACP

这个设置影响的是 CP_THREAD_ACP
ATL 中的 W2A\A2W,使用的都是线程的代码页。
在开发配置文件时,建议使用 UTF-8 编码格式,这样在中文、英文系统中都不会有读写问题。否则,如果只是使用 CP_THREAD_ACP,当操作系统语言变更时,就会出现读写乱码的问题。
WritePrivateProfileString
INI 文件读写 API:WritePrivateProfileString
- MSDN:文件不存在就创建,使用 ANSI 编码;如果存在 Unicode 编码文件,则 写入 Unicode 字符。
- 这里的 Unicode 编码实际指:UTF-16 编码(小端)
from 根据文件是否已经存在以及(如果存在)文件的内容编码方式,可能会出现问题。
- 如果 ini 文件的内容已经是 Unicode,则将其视为 Unicode。
- 在内部,这似乎由 IsTextUnicode 函数。
- 对于此功能,文件中正确的 BOM 是 Unicode 的重要提示。 因此,仅使用 WritePrivateProfileStringW 不能确保将 Unicode 写入 ini 文件,而是必须准备文件。
创建方法:先 utf-16-le 编码,再加上 BOM 头 \xff\xfe 。
inifile = os.path.join(uploaddir, "books.ini")
booksini = b"\xff\xfe" + booksini.encode("utf-16-le")
writefile(inifile, booksini)
#openTextFile(inifile)
Windows 记事本“另存为”中的编码
- ANSI,不同版本系统不一样,同一系统不同设置也不一样。
- Unicode,实际指代的是 UTF-16(小端)。
- Unicode big endian,实际是 UTF-16(大端)
- UTF-8,实际是带 BOM 头的 UTF-8 编码
Windows 记事本中输入“连”,ctrl+s 保存后再打开。 文件内容 16 进制为:0xC1AC,转成二进制:1100 0001 1010 1100,命中 UTF-8 的两字节编码规则 (110xxxxx 10xxxxxx),被识别成 UTF-8 编码。 当做 UTF-8 解码,得到 U+6C,但是不在 U+0080-U+07FF 之间,被当做错误 编码。
ANSI 编码,但是二进制能命中 UTF8 规则,但是又找不到 UTF8 对应的字符。
注册表与权限
注册表介绍
Windows 目录中 system.dat、user.dat 和 config.pol 文件 (regedit.exe)
除了 HKEY_CURRENT_USER 之外的所有支持文件都保存在 C:\Windows\System32\config。 HKEY_CURRENT_USER 的支持文件存储在您的个人资料文件夹中,%UserProfile%\Ntuser.dat
- HKEY_CLASSES_ROOT
- HKEY_CURRENT_USER
- HKEY_LOCAL_MACHINE
- HKEY_USERS
- HKEY_CURRENT_CONFIG
- HKEY_DYN_DATA
| 显示类型(在编辑器中) | 数据类型 | 说明 |
|---|---|---|
| REG_SZ | 字符串 | 文本字符串 |
| REG_MULTI_SZ | 多字符串 | 含有多个文本值的字符串 |
| REG_BINARY | 二进制数 | 二进制值,以十六进制显示 |
| REG_DWORD | 双字 | 一个 32 位的二进制值 |
| REG_QWORD | 四字 | 一个 64 位的二进制值 |
注册表操作
权限管理
- 普通用户 可以操作 HKEY_CURRENT_USER,无法操作 HKEY_LOCAL_MACHINE
- 管理员 可以操作 HKEY_CURRENT_USER、HKEY_LOCAL_MACHINE
- 服务 可以操作 HKEY_LOCAL_MACHINE,操作 HKEY_CURRENT_USER 需要获取模拟当前用户,或者获取当前用户的 id,读取 HKEY_USER 下面的值
什么是 UAC
概念
UAC 是 User Account Control 的缩写,其中文翻译为用户帐户控制,是微软在 Windows Vista 和 Win7 中引用的新技术,主要功能是进行一些会影响系统安全的操作时,会自动触发 UAC,用户确认后才能执行,从而保证系统安全。
触发 UAC 提示的操作:
- 修改 Windows Update 配置
- 增加或删除用户帐户
- 改变用户的帐户类型
- 改变 UAC 设置
- 安装 ActiveX
- 安装或卸载程序
- 安装设备驱动程序
- 修改和设置家长控制
- 增加或修改注册表
- 将文件移动或复制到 Program Files 或是 Windows 目录
UAC 的级别
最低的级别(0 级):关闭 UAC 功能(必须重新启动后才能生效)。在该级别下,如果是以管理员登录,则所有操作都将直接运行而不会有任何通知,包括病毒或木马对系统进行的修改。在此级别下,病毒或木马可以任意连接访问网络中的其他电脑、甚至与互联网上的电脑进行通信或数据传输。可见如果完全关闭 UAC 并以管理员身份登录,将严重降低系统安全性。此外,如果是以标准用户登录,那么安装、升级软件或对系统进行修改和设置,将直接被拒绝而不弹出任何提示,用户只有获得管理员权限才能进行。可见完全关闭 UAC 并以标准用户登录,各种操作和设置也非常不方便,因此建议不要选择该级别。
比默认级别稍低的级别(1 级):该级别不启用安全桌面,也就是说有可能产生绕过 UAC 更改系统设置的情况。不过一般情况下,如果是用户启动某些程序而需要对系统进行修改,可以直接运行,不会产生安全问题。但如果用户没有运行任何程序却弹出提示窗口,则有可能是恶意程序在试图修改系统设置,此时应果断选择阻止。该级别适用于有一定系统经验的用户。
默认级别(2 级):在默认级别下,只有在应用程序试图改变计算机设置时才会提示用户,而用户主动对 Windows 进行更改设置则不会提示。同时,在该模式下将启用安全桌面,以防绕过 UAC 更改系统设置。可以看出,默认级别可以既不干扰用户的正常操作,又可以有效防范恶意程序在用户不知情的情况下修改系统设置。一般的用户都可以采用该级别设置。
最高级别(3 级):在高级级别下,“始终通知”(即完全开启),在该级别下,用户安装应用程序、对软件进行升级、应用程序在任何情况下对操作系统进行更改、更改 Windows 设置等情况,都会弹出提示窗口(并启用安全桌面),请求用户确认。由此可见该级别是最安全的级别,但同时也是最“麻烦”的级别,适用于多人共用一台电脑的情况下,限制其他标准用户,禁止其随意更改系统设置。
为什么需要 UAC
这里需要说到一个概念:Host-based Intrusion Prevention System HIPS,基于主机的入侵防御系统。HIPS 是一种系统控制软件,它能监控电脑中文件的运行,对文件的调用,以及对注册表的修改。HIPS 可以分为 3D,AD(Application Defend)–应用程序防御体系、RD(Registry Defend) 注册表防御体系、FD(File Defend)文件防御体系。UAC 可以理解为一个基础的 HIPS 防御系统。杀毒软件的更新永远要追着病毒来,这种滞后性使得病毒有机会利用时间差攻击系统;而对杀毒软件而言,亡羊补牢就意味着重大的失败。这种情况下,要谋求更高的安全性,HIPS 成为了当然之选。
UAC 与兼容性
经常有人抱怨 NT6.x 系统的兼容性多么多么差,身边也有人因为“不兼容”而将系统换回 XP。但从我个人的使用看,几乎所有的软件都能很好的工作于 NT6.x 上。区别在哪?排除掉确实因为软件开发导致的兼容性问题的话,普通用户只会双击运行程序,而我在一次尝试失败后会根据程序行为对其进行手动提权。刚从 XP 过来的用户,估计不会有那么一套权限划分的意识,UAC 在某种程度上而言也就削弱了系统对普通用户的兼容性。但我们如果能够根据程序行为对需要的程序进行手动提权,所谓“兼容性问题”也就迎刃而解了。对用户水平更高的需求?也许吧。但计算机从来都是与永无休止的学习联系在一起的。而如果程序的开发能进一步的规范化,内置提权申请的程序就不存在被 UAC 影响兼容性的问题了。
UAC bypass
ref
ref  目前公开的方法中,有以下几种方法绕过 UAC:
目前公开的方法中,有以下几种方法绕过 UAC:
- 白名单提权机制
- DLL 劫持
- Windows 自身漏洞提权
- 远程注入
- COM 接口技术
针对新版 win10 有效的绕过 UAC 的几种方案 [UAC-bypass.md]
Bypass UAC by hijacking a DLL located in the Native Image Cache https://github.com/AzAgarampur/byeintegrity-uac
高低权限通信问题
服务和管理员、普通用户无法进行消息通信,需要做特殊过滤 ChangeWindowMessageFilter
- 普通用户无法操作 C:\Program Files (x86),会访问
C:\Users\当前登录计算机用户名\AppData\Local\VirtualStore\Program Files\下目录的的文本文件,需要加特殊过滤。
注册表优化
个性化设置
用作开机标识的注册表

进程与线程

进程就好比工厂里的车间,它代表 CPU 所能处理的单个任务。一个工厂可以有一到多个车间。
终止进程的四种方式
- 主线程的入口点函数返回
- 最正常的方式
- 某个线程调用 ExitProcess
- VOID ExitProcess(UINT uExitCode);
- 指定 ExitCode 强行退出进程,不推荐
- 另一个进程调用 TerminateProcess
- BOOL TerminateProcess(HANDLE hProcess, UINT uExitCode)
- 需要有 PROCESS_TERMINATE 权限
- 所有线程都“自然死亡”
终止线程的四种方式
- 线程函数返回,推荐做法
- ExitThread/_endthreadex 杀死自己,不推荐
- TerminateThread 避免使用
- 包含线程的进程终止运行,不可控
等待内核对象
DWORD WaitForSingleObject(
HANDLE hHandle,
DWORD dwMilliseconds
);
DWORD WaitForMultipleObjects(
DWORD nCount,
const HANDLE* lpHandles,
BOOL bWaitAll,
DWORD dwMilliseconds
);
WAIT_OBJECT_0 + nCount – 1
WAIT_TIMEOUT
WAIT_FAILED
HANDLE 内核对象 进程、线程、作业 文件、控制台的输入输出流、错误流互斥量、信号量、事件可等待的计时器
关键段(临界区)
void InitializeCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
void DeleteCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
void EnterCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
void LeaveCriticalSection(LPCRITICAL_SECTIONlpCriticalSection);
BOOL InitializeCriticalSectionAndSpinCount(
LPCRITICAL_SECTION lpCriticalSection,
DWORD dwSpinCount);
由于将线程切换到等待状态(切换内核模式)的开销较大,因此为了提高关键段的性能,Microsoft 将旋转锁合并到关键段中,这样 EnterCriticalSection() 会先用一个旋转锁不断循环,尝试一段时间才会将线程切换到等待状态。 旋转次数一般设置为 4000。
读写锁
读写锁 SRWLock
VOID InitializeSRWLock(PSRWLOCK SRWLock);
// 写入者线程申请写资源
VOID AcquireSRWLockExclusive(PSRWLOCK SRWLock);
VOID ReleaseSRWLockExclusive(PSRWLOCK SRWLock);
// 读取者线程申请读资源
VOID AcquireSRWLockShared(PSRWLOCK SRWLock);
VOID ReleaseSRWLockShared(PSRWLOCK SRWLock);
不常用,读取者可以并发执行。
事件
HANDLE CreateEvent(
LPSECURITY_ATTRIBUTES lpEventAttributes,
BOOL bManualReset,
BOOL bInitialState,
LPCTSTR lpName);
HANDLE OpenEvent(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
LPCTSTR lpName);
BOOL SetEvent(HANDLE hEvent);
BOOL ResetEvent(HANDLE hEvent);
信号量
HANDLE CreateSemaphore(
LPSECURITY_ATTRIBUTES lpSemaphoreAttributes,
LONG lInitialCount,
LONG lMaximumCount,
LPCTSTR lpName);
HANDLE OpenSemaphore(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
LPCTSTR lpName);
BOOL ReleaseSemaphore(
HANDLE hSemaphore,
LONG lReleaseCount,
LPLONG lpPreviousCount);
互斥体
HANDLE CreateMutex(
LPSECURITY_ATTRIBUTES lpMutexAttributes,
BOOL bInitialOwner,
LPCTSTR lpName);
HANDLE OpenMutex(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
LPCTSTR lpName);
ReleaseMutex
共享内存
HANDLE CreateFileMapping(
HANDLE hFile, // 物理文件句柄
LPSECURITY_ATTRIBUTES lpAttributes, // 安全设置
DWORD flProtect, // 保护设置 PAGE_READWRITE | SEC_COMMIT
DWORD dwMaximumSizeHigh,
DWORD dwMaximumSizeLow,
LPCTSTR lpName // 共享内存名称
);
LPVOID WINAPI MapViewOfFile(
HANDLE hFileMappingObject,
DWORD dwDesiredAccess,
DWORD dwFileOffsetHigh,
DWORD dwFileOffsetLow,
SIZE_T dwNumberOfBytesToMap
);
命名管道
HANDLE CreateNamedPipe(
LPCTSTR lpName, // 指向管道名称的指针
DWORD dwOpenMode, // 管道打开模式
DWORD dwPipeMode, // 管道模式
DWORD nMaxInstances, // 最大实例数
DWORD nOutBufferSize, // 输出缓存大小
DWORD nInBufferSize, // 输入缓存大小
DWORD nDefaultTimeOut, // 超时设置
LPSECURITY_ATTRIBUTES lpSecurityAttributes // 安全属性指针
);
命名管道
服务器的实现过程
- 创建命名管道:CreateNamedPipe
- 等待客户端连接:ConnectNamedPipe
- 读取客户端请求数据:ReadFile
- 向客户端回复数据:WriteFile
- 关闭连接:DisconnectNamedPipe
- 关闭管道:CloseHandle
客户端实现过程
- 打开命名管道:CreateFile
- 等待服务端响应:WaitNamedPipe
- 切换管道为读模式:SetNamedPipeHandleState
- 向服务端发数据:WriteFile
- 读服务端返回的数据:ReadFile
- 关闭管道:CloseHandle
关于 _beginthreadex _tiddate
unsigned long _beginthreadex(
void *security,
unsigned stack_size,
unsigned(_stdcall *start_address)(void *),
void *argilist,
unsigned initflag,
unsigned *threaddr // 用来接收线程 ID
);
_beginthreadex 是一个 C/C++ 运行库函数。和 CreateThread 一样创建线程。 但是它们两者是有区别的。
- 每个线程都有自己的 _tiddata 内存块,从 C/C++ 运行库的堆上分配而来
- 传过来的线程函数的地址和要传入的参数都保存在这个数据块中
- 在 _beginthreadex 内部调用 CreateThead 时,传过去的地址是 _threadstartex 地址而不是
- 配对使用 _endthreadex
- 不要使用 _beginthread
- 因为 _beginthreadex 和 _endthreadex 是 CRT 线程函数,所以必须注意编译选项 runtimelibaray 的选择,使用 MT 或 MTD。
- _beginthreadex
- 每个线程均获得由 C/C++ 运行期库的堆栈分配的自己的 tiddata 内存结构。
- 传递给 _beginthreadex 的线程函数的地址保存在 tiddata 内存块中。传递给该函数的参数也保存在该数据块中。
- _beginthreadex 确实从内部调用 CreateThread,因为这是操作系统了解如何创建新线程的唯一方法。
- 当调用 CreatetThread 时,它被告知通过调用 _threadstartex 而不是 pfnStartAddr 来启动执行新线程。 还有,传递给线程函数的参数是 tiddata 结构而不是 pvParam 的地址。
- 如果一切顺利,就会像 CreateThread 那样返回线程句柄。如果任何操作失败了,便返回 NULL。
- _endthreadex
- C 运行期库的 _getptd 函数内部调用操作系统的 TlsGetValue 函数,该函数负责检索调用线程的 tiddata 内存块的地址。
- 然后该数据块被释放,而操作系统的 ExitThread 函数被调用,以便真正撤消该线程。当然,退出代码要正确地设置和传递。
- 虽然也提供了简化版的的 _beginthread 和 _endthread,但是可控制性太差,所以一般不使用。
- 线程 handle 因为是内核对象,所以需要在最后 closehandle。
- 更多的 API:
- HANDLE GetCurrentProcess();
- HANDLE GetCurrentThread();
- DWORD GetCurrentProcessId();
- DWORD GetCurrentThreadId()。
- DWORD SetThreadIdealProcessor(HANDLE hThread, DWORD dwIdealProcessor);
- BOOL SetThreadPriority(HANDLE hThread, int nPriority);
- BOOL SetPriorityClass(GetCurrentProcess(), IDLE_PRIORITY_CLASS);
- BOOL GetThreadContext(HANDLE hThread, PCONTEXT pContext);
- BOOL SwitchToThread();
- C++ 主线程的终止,同时也会终止所有主线程创建的子线程,不管子线程有没有执行完毕。 所以上面的代码中如果不调用 WaitForSingleObject,则 2 个子线程 t1 和 t2 可能并没有执行完毕或根本没有执行。
- 如果某线程挂起,然后有调用 WaitForSingleObject 等待该线程,就会导致死锁。所以上面的代码如果不调用 resumethread,则会死锁。
内存管理
用户模式与内核模式
- 应用程序运行在用户模式
- 操作系统组件和驱动程序运行在内核模式(某些驱动程序能以用户模式运行)
- 处理器根据运行的代码的类型,在用户模式与内核模式切换

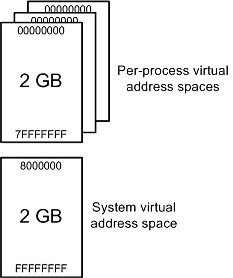
虚拟地址空间
- 在 32 位 Windows 中,可用的虚拟地址空间共计为 2^32 字节(4GB),较低的 2 GB 用于用户空间,较 高的 2 GB 用于内核地址空间(可通过 BCDEdit /set increaseuserva 命令调整 https://docs.microsoft.com/zh-cn/windows-hardware/drivers/devtest/bcdedit--set
- 在 64 位 Windows 中,可用的虚拟地址空间的理论大小为 2^64 字节(16EB),但实际上仅使用 16 EB 范围 的一小部分,在 win8 及以前用户空间为和内核地址空间都为 8TB,win8.1 及以后都是 128TB

裸指针的使用

内存移动 & 内存拷贝
- memmove_s 如果源区域和目标区域的某些区域重叠,memmove_s 会确保重叠区域中的原始源字符在被覆盖之前被复制。
- MoveMemory 第一个参数 Destination 必须足够大,以容纳源的长度字节;否则,可能会发生缓冲区溢出。
- memcpy_s 如果源和目标重叠,则 memcpy_s 的行为未定义。使用 memmove 处理重叠区域
- CopyMemory RtlCopyMemory 运行速度比 RtlMoveMemory 快,但 RtlCopyMemory 要求源和目的地的内存块不重叠
内存对齐
- 为了提高内存的访问速度(数据存放地址不为偶数时需要两个时钟周期才能取到想要的数据)
- 结构体自身需要对齐
- 其大小按被能被其最大对齐值整除
- 结构体偏移被能被其最大对齐值整除
- 结构体中的元素需要对齐
- 偏移按按自身对齐值或指定对齐最小值的整倍对齐



- 强制指定对齐方式
- #pragma pack(N)
- 网络数据传输时,字节对齐问题可能会引发各种莫名其妙的 bug
智能指针
CComPtr & CComQIPtr。

使用智能指针的情况

不使用智能指针的情况
推荐使用 std::make_shared 来生成 std::shared_ptr
- std::shared_ptr
sp(new Widget); 会有两次内存分配 - auto sp = std::make_shared
(); 只有一次内存分配 - 提供了更好的异常安全性


分配内存
- new operator
- 分配内存
- 在内存块上调用构造函数
- 返回对象指针
行为等价于:
- operator new
- palcement new
- 返回对象指针
placement new
- 在指定的地址空间中调用构造函数
- placement new 是对 operator new 的重载
int main() {
std::string* p = new std::string("test");
void p1 = operator new(strlen("test"));
std::string* p2 = new(p1) std::string("test");
return 1;
}
inline void* __CRTDECL operator new(
size_t _Size,
_Writable_bytes_(_Size) void* _Where) noexcept {
(void) _Size;
return _Where;
}
什么时候用:
- 需要将内存分配与构造分开执行时(比如自定义内存池)
- 需要自己控制内存的分配与释放
注意:
- 不要忘记调用析构函数完成反初始化
- placement new 和 placement delete 要配对重载
operator new[]
int main() {
Test* p = new Test[10];
delete[] p;
}
Test::`vector deleting destructor':
push offset Test::~Test (0B115FAh)
mov eax, dword ptr [this]
mov ecx, dword ptr [eax-4] // 往前移 4 字节,取出数组数目。
push ecx
push 8
new(std::nothrow)
- 不使用 std::nothrow 时,内存分配失败会抛异常
- 使用 std::nothrow 后内存分配失败时返回 NULL
malloc/free(需配对使用)
- malloc 依赖运行时库
- 在 windows 下 malloc 底层是调用 HeapAlloc 实现堆内存分配
- malloc 直接返回申请到的内存地址,申请内存失败直接返回 NULL 指针
注意:
- 跨模块使用时,切勿传递 malloc 或 new 以及标准库对象指针
VirtualAlloc/VirtualFree(需配对使用)
- 按页分配虚拟内存(一页 4K)
- 属于系统级的 API
- 可以指定分配内存的保护属性
- 可以先预定内存而不使用,待真正需要时才提交到物理内存
LPVOID VirtualAlloc(
LPVOID lpAddress,
SIZE_T dwSize,
DWORD flAllocationType,
DWORD flProtect
);
关于使用 MEM_RESERVE
- 需要提前占用指定的虚拟地址时
- 需要大量申请虚拟内存,按后按需再提交到内存
MEM_RESERVE 0x00002000
Reserves a range of the process's virtual address space without allocating any actual physical storage in memory or in the paging file on disk. You can commit reserved pages in subsequent calls to the VirtualAlloc function. To reserve and commit pages in one step, call VirtualAlloc with MEM_COMMIT | MEM_RESERVE.
Other memory allocation functions, such as malloc and LocalAlloc, cannot use a reserved range of memory until it is released.
VirtualQuery 查询内存信息
实例:已知一 PE 文件某全局变量的地址求该 PE 文件的基地址

gonghang plugin bugfix
VirtualProtect 修改内存属性
实例:将分配的内存修改为读写状态
BOOL VirtualProtect(
LPVOID lpAddress,
SIZE_T dwSize,
DWORD flNewProtect,
PDWORD lpflOldProtect
);
堆分配 HeapAlloc/HeapFree
- 它是对 VirtualAlloc 的封装,内存利用率会比 VirtualAlloc 高
- 每个进程都有缺省的进程堆,通过 GetProcessHeap 可获取
- 除了默认读,还可以可以创建私有堆 HeapCreate
- 堆内存提高了内存的利用率,简化了虚拟内存的分配
- malloc 使用堆内存
- 小大粒度为 16 字节
关于堆的 HEAP_NO_SERIALIZE 标志
- 默认的进程堆是序列化的,序列化堆是线程安全的(会有性能损耗)
- HEAP_NO_SERIALIZE 表示对堆的使用是线程不安全的
- 何时使用 HEAP_NO_SERIALIZE 标志
- 单线程情况
- 多线程情况下,但只在特定的线程才使用指定的堆
- 多线程情况下,自身提供互斥机制保证堆安全
- 如果非三种情况下使用 HEAP_NO_SERIALIZE 将导致堆损坏
GlobalAlloc/LocalAlloc
- 是 HeapAlloc 的封装,效率较低,不再推荐使用
总结:

- VirtualAlloc 允许指定内存分配的附加属性,如 MEM_RESERVE、PAGE_EXECUTE_READ,使用灵 活,但是分配以页为粒度,会导致高内存使用
- HeapAlloc 函数底层依赖 VirtualAlloc,它能提供更方便的内存分配,具有更小的粒度
- malloc 依赖运行时库,在 windows 下是对堆函数的高级封装
- new 依赖于编译器和语言实现
文件映射
- 文件映射的使用
- 实现文件内容与虚拟内存的关联访问
- 实现跨进程内存共享
- 实现快速的大文件访问
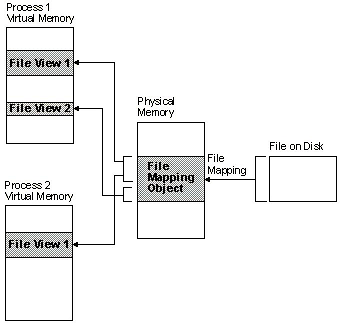
注意:
- 文件映射对象创建好之后,无法再调整大小,所以需一次性准备好大小(建议设置为 0)
- 当指定的大小小于文件文件时将只有部分内容被映射
- 当指定的大小大于文件的大小时,文件将被扩大
- 如果需将内存数据写入磁盘,为避免数据丢失,需调用 FlushViewOfFile 将内存数据刷入磁盘
单进程模式应用:



from
C/C++ 实现 PE 文件特征码识别,打开 PE 文件映射:
在读取 PE 结构之前,首先要做的就是打开 PE 文件到内存,这里打开文件我们使用了 CreateFile() 函数该函数可以打开文件并返回文件句柄, 接着使用 CreateFileMapping() 函数创建文件的内存映像,最后使用 MapViewOfFile() 读取映射中的内存并返回一个句柄, 后面的程序就可以通过该句柄操作打开后的文件了。
内存可读写判断
IsBadReadPtr
IsBadWritePtr
IsBadCodePtr
跨进程内存操作
VirtualAllocEx
WriteProcessMemory


内存池
应用程序频繁地在堆上分配和释放内存,会导致性能的损失。并且会使系统中出现大量的内存碎片,降低内存的利用率。 默认的分配和释放内存算法自然也考虑了性能,然而这些内存管理算法的通用版本为了应付更复杂、更广泛的情况,需要做更多的额外工作。 而对于某一个具体的应用程序来说,适合自身特定的内存分配释放模式的自定义内存池可以获得更好的性能。

- 伙伴算法,用于管理物理内存,避免内存碎片;
- 高速缓存 Slab 层用于管理内核分配内存,避免碎片。
Windows 文件读写
NTFS vs FAT32 vs exFAT
- NTFS 是带日志的现代文件系统,基本上是 Windows 专属
- FAT32 和 exFAT 本质上还是一类,核心区别在于 FAT32 单文件最大 4GB,大多数操作系统都支持这两个文件系统(XP 需要安装某个补丁)

文件系统介绍 - 鸟瞰

Maximum Path Length Limitation
https://docs.microsoft.com/en-us/windows/win32/fileio/maximum-file-path-limitation?tabs=cmd
超过 MAX_PATH 怎么办?
\\?\D:\very long path
什么是路径的 domain
DWORD GetShortPathNameA(
[in] LPCSTR lpszLongPath,
[out] LPSTR lpszShortPath,
[in] DWORD cchBuffer
);
缓冲区刷进磁盘的时机:
- 等缓冲区满了(被动)
- 手工调用 fflush、FlushFileBuffers(主动)
- 文件关闭
异步文件读写
WriteFileEx function (fileapi.h)
BOOL WriteFileEx(
[in] HANDLE hFile,
[in, optional] LPCVOID lpBuffer,
[in] DWORD nNumberOfBytesToWrite,
[in, out] LPOVERLAPPED lpOverlapped,
[in] LPOVERLAPPED_COMPLETION_ROUTINE lpCompletionRoutine
);
异步的高层选择:libuv
Nodejs = libuv + v8 跨平台异步 I/O 封装,在 Windows 上实现是 IOCP,在 Linux 上是 epoll
Windows 平台上与 kqueue (FreeBSD) 或者 (e)poll(Linux) 等内核事件通知相应的机制是 IOCP。 libuv 提供了一个跨平台的抽象,由平台决定使用 libev 或 IOCP。 libuv 异步文件系统: https://luohaha.github.io/Chinese-uvbook/source/filesystem.html
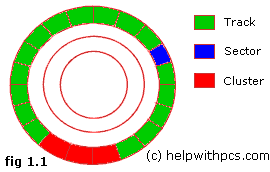
Sector 和 Cluster
- 你调用 API 写一个 byte,会触:
- 发文件系统发送 IRP_MJ_WRITE 给 volume 设备
- volume 设备发送 IRP_MJ_WRITE 给 disk 设备
- disk 收到的是一个 cluster size 的写
- sector 的 size 不是固定的
- cluster 是 sector 的整数倍,倍数也不固定
- 为什么读写会被放大:因为管理颗粒越小带来的管理代价越大(如:bitmap)
怎么使用读写锁
- 先初始化:InitializeSRWLock
- 读:1.AcquireSRWLockShared,2. 读文件,3.ReleaseSRWLockShared
- 写:1.AcquireSRWLockExclusive,2. 写文件,3.ReleaseSRWLockExclusive
- 使用原则:先获取锁,干事情,释放锁
- 有 Acquire,就一定要有对应的 Release○Acquire 什么类型的锁,Release 也要是这个类型的锁
- Exclusive 锁不能重入(同一个线程 TryAcquireSRWLockExclusive 成功后就不能再次 TryAcquireSRWLockExclusive)
读写 ini 文件
使用 API 写的问题,失败了不能确定是否破坏了其他项目的内容
json
注意 64 位的精度
案例:特殊路径
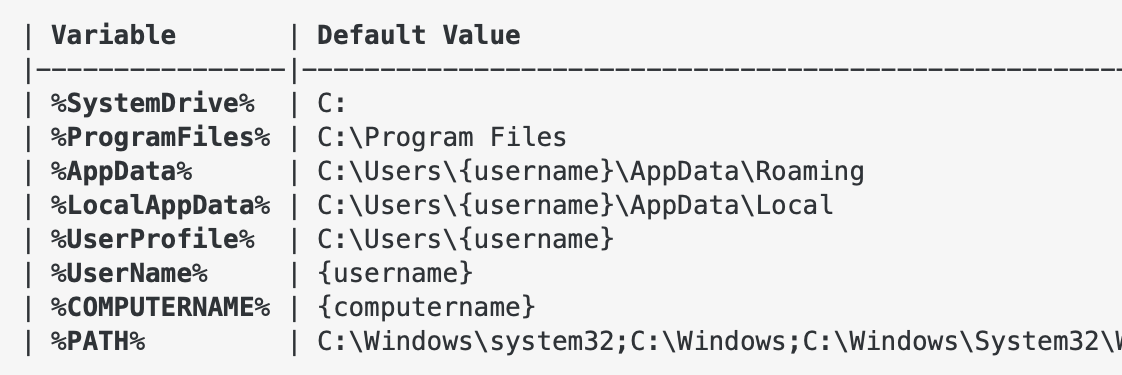
特殊路径
界面 BkWin 教程
IconToBitmap 并保留 Alpha 通道。
float KFunction::GetCurrentDpi() {
DWORD dwDpi = 96;
do {
KRegister2 reg;
if (reg.Open(HKEY_CURRENT_USER,
L"Control Panel\\Desktop\\WindowMetrics") &&
reg.Read(L"AppliedDPI", dwDpi)) {
break;
}
} while (FALSE);
return dwDpi;
}
HBITMAP CCPdfmenushell::_IconToBitmap(int iconResId)
{
float fdpi = KFunction::GetCurrentDpi() * 1.f / 96;
int nIconSize = int(fdpi * 16 + 0.5f);
HICON hIcon = (HICON)::LoadImage((HINSTANCE)&__ImageBase,
MAKEINTRESOURCE(iconResId),
IMAGE_ICON,
nIconSize,
nIconSize,
LR_DEFAULTCOLOR);
ICONINFO info = { 0 };
if (hIcon == NULL || !GetIconInfo(hIcon, &info) || !info.fIcon) {
if (hIcon) { ::DestroyIcon(hIcon); }
return NULL;
}
INT nWidth = 0;
INT nHeight = 0;
if (info.hbmColor != NULL) {
BITMAP bmp = { 0 };
GetObject(info.hbmColor, sizeof(bmp), &bmp);
nWidth = bmp.bmWidth;
nHeight = bmp.bmHeight;
}
if (info.hbmColor != NULL) {
DeleteObject(info.hbmColor);
info.hbmColor = NULL;
}
if (info.hbmMask != NULL) {
DeleteObject(info.hbmMask);
info.hbmMask = NULL;
}
if (nWidth <= 0 || nHeight <= 0) {
if (hIcon) { ::DestroyIcon(hIcon); }
return NULL;
}
INT nPixelCount = nWidth * nHeight;
HDC dc = GetDC(NULL);
INT* pData = NULL;
HDC dcMem = NULL;
HBITMAP hBmpOld = NULL;
bool* pOpaque = NULL;
HBITMAP dib = NULL;
BOOL bSuccess = FALSE;
if (dc == NULL) {
if (hIcon) { ::DestroyIcon(hIcon); }
return NULL;
}
do {
BITMAPINFOHEADER bi = { 0 };
bi.biSize = sizeof(BITMAPINFOHEADER);
bi.biWidth = nWidth;
bi.biHeight = -nHeight;
bi.biPlanes = 1;
bi.biBitCount = 32;
bi.biCompression = BI_RGB;
dib = CreateDIBSection(dc, (BITMAPINFO*)&bi, DIB_RGB_COLORS, (VOID**)&pData, NULL, 0);
if (dib == NULL) break;
memset(pData, 0, nPixelCount * 4);
dcMem = CreateCompatibleDC(dc);
if (dcMem == NULL) break;
hBmpOld = (HBITMAP)SelectObject(dcMem, dib);
::DrawIconEx(dcMem, 0, 0, hIcon, nWidth, nHeight, 0, NULL, DI_MASK);
pOpaque = new (std::nothrow) bool[nPixelCount];
if (pOpaque == NULL) break;
for (INT i = 0; i < nPixelCount; ++i) {
pOpaque[i] = !pData[i];
}
memset(pData, 0, nPixelCount * 4);
::DrawIconEx(dcMem, 0, 0, hIcon, nWidth, nHeight, 0, NULL, DI_NORMAL);
BOOL bPixelHasAlpha = FALSE;
UINT* pPixel = (UINT*)pData;
for (INT i = 0; i < nPixelCount; ++i, ++pPixel) {
if ((*pPixel & 0xff000000) != 0) {
bPixelHasAlpha = TRUE;
break;
}
}
if (!bPixelHasAlpha) {
pPixel = (UINT*)pData;
for (INT i = 0; i < nPixelCount; ++i, ++pPixel) {
if (pOpaque[i]) {
*pPixel |= 0xFF000000;
} else {
*pPixel &= 0x00FFFFFF;
}
}
}
bSuccess = TRUE;
} while (FALSE);
if (pOpaque != NULL) {
delete[]pOpaque;
pOpaque = NULL;
}
if (dcMem != NULL) {
SelectObject(dcMem, hBmpOld);
DeleteDC(dcMem);
}
ReleaseDC(NULL, dc);
if (!bSuccess) {
if (dib != NULL) {
DeleteObject(dib);
dib = NULL;
}
}
if (hIcon) { ::DestroyIcon(hIcon); }
return dib;
}
UI 控件 drawableview
支持托管控件绘制,该控件是 IBkWindowPaintHook 替代解决方案 强烈建议不使用 BkWindowPaintHook
开源许可证教程

如何选择开源协议 世界上的开源协议有上百种(有兴趣的读者请猛击 这里 了解),很少有人能彻底搞清它们之间的区别,即使在最流行的六种开源协议 —— GPL、BSD、MIT、Mozilla、Apache 和 LGPL —— 之中做选择,也很复杂。
乌克兰程序员 Paul Bagwell 画了一张分析图,说明应该怎么选择开源协议,大家看了一目了然,真是清爽。 图片来自于阮一峰博客:如何选择开源协议

参考资料快照
- https://docs.microsoft.com/zh-cn/visualstudio/profiling/?view=vs-2019
- https://docs.microsoft.com/zh-cn/visualstudio/debugger/?view=vs-2019
- https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/getting-started-with-windbg
- https://docs.microsoft.com/zh-cn/windows/win32/sync/synchronization-objects
- https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
- https://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php
- https://www.cnblogs.com/batsing/p/charset.html
- http://archives.miloush.net/michkap/archive/2006/09/15/754992.html
- https://0x00-0x00.github.io/research/2018/10/31/How-to-bypass-UAC-in-newer-Windows-versions.html
- https://github.com/AzAgarampur/byeintegrity-uac
- https://docs.microsoft.com/zh-cn/windows-hardware/drivers/devtest/bcdedit–set
- https://docs.microsoft.com/en-us/windows/win32/memory/reserving-and-committing-memory
- https://www.cnblogs.com/LyShark/p/13666403.html
- https://blog.csdn.net/aurorayqz/article/details/79671785
- https://docs.microsoft.com/en-us/windows/win32/fileio/maximum-file-path-limitation?tabs=cmd
- https://luohaha.github.io/Chinese-uvbook/source/filesystem.html
- https://mp.weixin.qq.com/s/RlQwINnU93CTgHd0EqKdnA?scene=25
- http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html
- https://www.gnu.org/licenses/license-list.html
- 编程与调试 -- Windows 编程知识点(文档整理)2/2 逆向 & 驱动 | 09 Jan 2022
- 编程与调试 -- Windows 编程知识点(文档整理)1/2 基础 | 20 Nov 2021
 .
.