编程与调试 C++ -- C++11 模板元编程 实现编译期字符串加密
反编译一个程序,我们往往通过 IDA 或者 windbg 从字符串入手。 如果我们能针对每个字符串加密,运行时解密,就能更好的把字符串信息进行隐藏。 而 C++11/C++14 的新特性 模板元编程 能实现编译期字符串加密。 并且还很好的保证了代码的可读性。
目标实现宏 OBFUSCATED ,编译出来的二进制文件,IDA 逆向分析不包含字符串 Baby Hai's Secret 。
std::string stdstr = OBFUSCATED("Baby Hai's Secret");
模板元编程
这玩意号称图灵完备的,很厉害,能实现编译期间运算,主要用到 模板偏特化 & 编译优化。
- 第一个版本,实现长度为 6 的字符串的编译时加密。
- 第二个版本,实现任意长度的字符串 编译时加密。
- 第三个版本,实现任意长度的字符串 随机 key 的编译时加密。
- 第四个版本,三个算法,随机选择加密。
算阶乘
阶乘定义:
N! = 1 * 2 * 3 * 4 * ... * N
N! = N * (N - 1)!
#include <iostream>
#include <type_traits>
template<int N>
struct Factorial
{
static const int value = N * Factorial<N - 1>::value;
};
template<>
struct Factorial<0>
{
static const int value = 1;
};
int main() {
// 编译期间 Factorial<5>::value 就算出来了。
std::cout << "Factorial(5) = " << Factorial<5>::value << std::endl;
return 0;
}
生成的汇编代码:

答案编译期就计算出来了, 5! = 0x78 = 120 。
enable_if
C++14 enable_if 。
编译器在类型推导的过程中,会尝试推导所有的重载函数,在此过程在过程中,如果 enable_if 条件不满足,则会在候选函数集合中剔除此函数。
#include <iostream>
#include <type_traits>
// 1. 只有当 T 是整数的时候,函数才存在。
template <class T>
typename std::enable_if<std::is_integral<T>::value, bool>::type
is_odd(T i) { return bool(i % 2); }
// 2. 只有当 T 是整数的时候,函数才存在。
template < class T,
class = typename std::enable_if<std::is_integral<T>::value>::type>
bool is_even(T i) { return !bool(i % 2); }
int main() {
short int i = 1; // 如果不是整数类型,编译不过。
//float i = 1; // 模板推导失败
std::cout << "i is odd: " << is_odd(i) << std::endl;
std::cout << "i is even: " << is_even(i) << std::endl;
return 0;
}
第一个版本
#include <iostream>
#include <type_traits>
template<int... I> // 字符串的数组下标。
struct MetaString1
{
// 编译期运算
constexpr __forceinline MetaString1(const char* str)
: m_buffer{ encrypt(str[I])... } { }
// 运行时解密
inline const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i) {
m_buffer[i] = decrypt(m_buffer[i]);
}
m_buffer[sizeof...(I)] = 0;
return m_buffer;
}
private:
// 加密一个字符
constexpr char encrypt(char c) const { return c ^ 0x55; }
// 解密一个字符
constexpr char decrypt(char c) const { return encrypt(c); }
private:
char m_buffer[sizeof...(I) + 1];
};
#define OBFUSCATED1(str) (MetaString1<0, 1, 2, 3, 4, 5>(str).decrypt())
int main() {
std::cout << OBFUSCATED1("123456789") << std::endl;
std::cout << OBFUSCATED1("123456") << std::endl;
std::cout << OBFUSCATED1("12345") << std::endl;
return 0;
}
输出:
123456
123456
12345
很明显,只能处理 6 个字符串的情况。
简化一下代码,编译 Release 看看汇编代码。
#include <iostream>
#include <type_traits>
template<int... I> // 字符串的数组下标。
struct MetaString1
{
// 编译期运算
constexpr __forceinline MetaString1(const char* str)
: m_buffer{ encrypt(str[I])... } {
}
// 运行时解密
const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i) {
m_buffer[i] = decrypt(m_buffer[i]);
}
m_buffer[sizeof...(I)] = 0;
return m_buffer;
}
private:
// 加密一个字符
constexpr char encrypt(char c) const { return c ^ 0x55; }
constexpr char decrypt(char c) const { return encrypt(c); }
private:
char m_buffer[sizeof...(I) + 1];
};
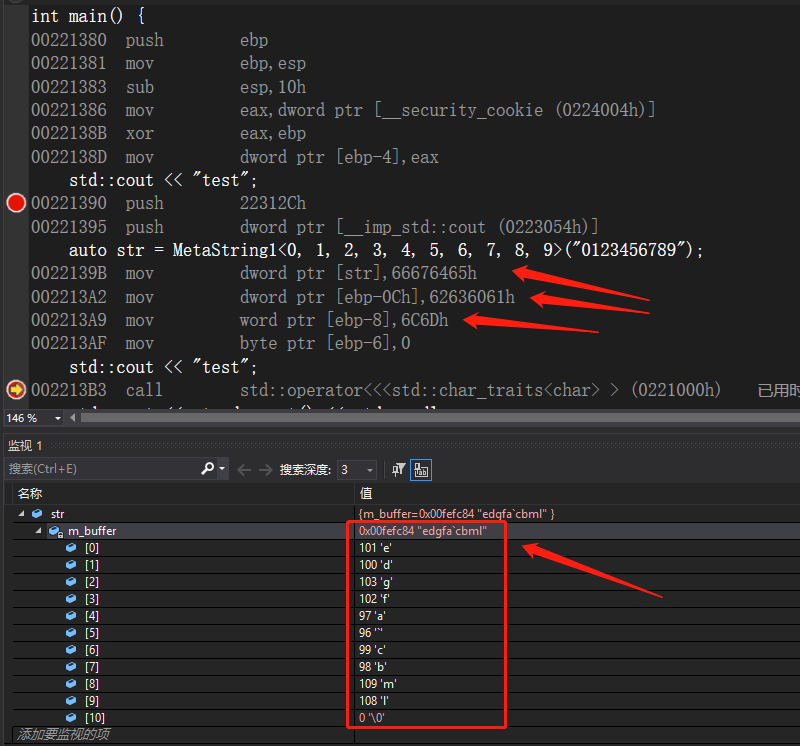
int main() {
auto str = MetaString1<0, 1, 2, 3, 4, 5, 6, 7, 8, 9>("0123456789");
std::cout << "test";
std::cout << str.decrypt() << std::endl;
return 0;
}
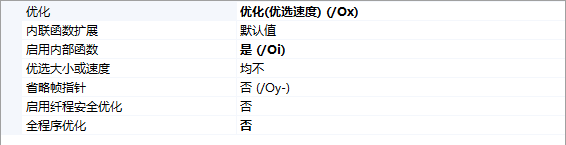
编译器设置:
编译后的汇编代码(都优化成了一堆 mov 指令):
Windows 是小端存储(低位在低地址):
>>> "%c" % chr(0x66 ^ 0x55) '3'
>>> "%c" % chr(0x67 ^ 0x55) '2'
>>> "%c" % chr(0x64 ^ 0x55) '1'
>>> "%c" % chr(0x65 ^ 0x55) '0'
第二个版本
自动识别字符串长度。 使用偏特化为每个长度的字符串自动生成一个模板。
// C++14 (C++1y) 新增 std::index_sequence
// MakeIndex<N>::type 生成 Indexes<0, 1, 2, 3, ..., N>
template<int... I>
struct Indexes { using type = Indexes<I..., sizeof...(I)>; };
template<int N>
struct Make_Indexes { using type = typename Make_Indexes<N - 1>::type::type; };
template<>
struct Make_Indexes<0> { using type = Indexes<>; };
完整版本:
#include <iostream>
#include <type_traits>
// C++14 (C++1y) 新增 std::index_sequence
// MakeIndex<N>::type 生成 Indexes<0, 1, 2, 3, ..., N>
template<int... I>
struct Indexes { using type = Indexes<I..., sizeof...(I)>; };
template<int N>
struct Make_Indexes { using type = typename Make_Indexes<N - 1>::type::type; };
template<>
struct Make_Indexes<0> { using type = Indexes<>; };
template<typename Indexes>
struct MetaString2;
template<int... I>
struct MetaString2<Indexes<I...>>
{
constexpr __forceinline MetaString2(const char* str)
: m_buffer{ encrypt(str[I])... } { }
inline const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i)
m_buffer[i] = decrypt(m_buffer[i]);
m_buffer[sizeof...(I)] = 0;
return m_buffer;
}
private:
constexpr char encrypt(char c) const { return c ^ 0x55; }
constexpr char decrypt(char c) const { return encrypt(c); }
private:
char m_buffer[sizeof...(I) + 1];
};
int main() {
#define cstr "123"
auto str = MetaString2<Make_Indexes<sizeof(cstr) - 1>::type>(cstr);
return 0;
}

第三个版本
上面的每次都是同一个密钥 0x55 ,能不能每次都采用不同的密钥呢。
用编译时 时间 __TIME__ 作为种子,生成编译期随机数。
宏 __COUNTER__ 是一个计数器,会从 0 开始计数,然后每次调用加 1。
__COUNTER__ 保证每个字符串 key 都不一样, __TIME__ 保证每次构建都不一样。
Predefined macros
完整的编译期随机数生成算法:
#include <iostream>
#include <type_traits>
#include <random>
namespace
{
constexpr char time[] = __TIME__; // 24 小时格式: hh:mm:ss
constexpr int DigitToInt(char c) { return c - '0'; }
const int seed = DigitToInt(time[7]) + DigitToInt(time[6]) * 10 + //
DigitToInt(time[4]) * 60 + DigitToInt(time[3]) * 600 + //
DigitToInt(time[1]) * 3600 + DigitToInt(time[0]) * 36000;
}
// 根据 N,生成随机数 value
template<int N>
struct MetaRandomGenerator
{
private:
static constexpr unsigned a = 16807; // 7^5
static constexpr unsigned m = 2147483647; // 2^31 - 1
static constexpr unsigned s = MetaRandomGenerator<N - 1>::value;
static constexpr unsigned lo = a * (s & 0xFFFF); // 低 16 位乘以 16807
static constexpr unsigned hi = a * (s >> 16); // 高 16 位乘以 16807
static constexpr unsigned result = lo + hi + ((hi & 0x7FFF) << 16);
public:
static constexpr unsigned max = m;
static constexpr unsigned value = result > m ? result - m : result;
};
template<>
struct MetaRandomGenerator<0>
{
static constexpr unsigned value = seed;
};
template<int N, int M>
struct MetaRandom
{
static const int value = MetaRandomGenerator<N + 1>::value % M;
};
int main() {
// 每次构建,会是一个不同的数字。
int v = MetaRandom<__COUNTER__, 10>::value;
int x = MetaRandom<__COUNTER__, 10>::value;
return 0;
}
完整代码:
template<typename Indexes, int K>
struct MetaString3;
template<int... I, int K>
struct MetaString3<Indexes<I...>, K>
{
// buffer[0] 存储 key。
constexpr __forceinline MetaString3(const char* str)
: m_buffer{ static_cast<char>(K), encrypt(str[I])... } { }
// 运行时间解密。
inline const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i)
m_buffer[i + 1] = decrypt(m_buffer[i + 1]);
m_buffer[sizeof...(I) + 1] = 0;
return m_buffer + 1;
}
private:
constexpr char key() const { return m_buffer[0]; }
constexpr char encrypt(char c) const { return c ^ key(); }
constexpr char decrypt(char c) const { return encrypt(c); }
private:
char m_buffer[sizeof...(I) + 2];
};
template<int N>
struct MetaRandomChar3
{
// 不能超过 0x7F
static const char value = static_cast<char>(1 + MetaRandom<N, 0x7F - 1>::value);
};
int main() {
#define cstr "1234"
auto temp = MetaString3<Make_Indexes<sizeof(cstr) - 1>::type, \
MetaRandomChar3<__COUNTER__>::value>(cstr);
return 0;
}
第四个版本
能不能实现多个算法,每次随机挑选一个呢。 实现三个算法,每次随机挑选一个。
模板偏特化 Template partial specialization:
template<int A, int K, typename Indexes>
struct MetaString4;
template<int K, int... I>
struct MetaString4<0, K, Indexes<I...>>
{ … c ^ K … };
template<int K, int... I>
struct MetaString4<1, K, Indexes<I...>>
{ … c + K … };
#define DEF_OBFUSCATED4(str) MetaString4<MetaRandom<__COUNTER__, 2>::value, …
完整实现:
// 三个参数:N - 算法,Key,Indexes - 字符串下标数组。
template<int N, char Key, typename Indexes>
struct MetaString;
第一个算法:
template<char K, int... I>
struct MetaString<0, K, Indexes<I...>>
{
constexpr __forceinline MetaString(const char* str)
: m_key{ K }, m_buffer{ encrypt(str[I], K)... } { }
inline const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i)
m_buffer[i] = decrypt(m_buffer[i]);
m_buffer[sizeof...(I)] = 0;
return const_cast<const char*>(m_buffer);
}
private:
constexpr char key() const { return m_key; }
constexpr char __forceinline encrypt(char c, int k) const { return c ^ k; }
constexpr char decrypt(char c) const { return encrypt(c, key()); }
volatile int m_key; // volatile 避免编译器过度优化。
volatile char m_buffer[sizeof...(I) + 1];
};
第二个算法:
template<char K, int... I>
struct MetaString<1, K, Indexes<I...>>
{
constexpr __forceinline MetaString(const char* str)
: m_key(K), m_buffer{ encrypt(str[I], I)... } { }
inline const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i)
m_buffer[i] = decrypt(m_buffer[i], i);
m_buffer[sizeof...(I)] = 0;
return const_cast<const char*>(m_buffer);
}
private:
constexpr char key(size_t position) const { return static_cast<char>(m_key + position); }
constexpr char __forceinline encrypt(char c, size_t position) const { return c ^ key(position); }
constexpr char decrypt(char c, size_t position) const { return encrypt(c, position); }
volatile int m_key;
volatile char m_buffer[sizeof...(I) + 1];
};
第三个算法:
template<char K, int... I>
struct MetaString<2, K, Indexes<I...>>
{
constexpr __forceinline MetaString(const char* str)
: m_buffer{ encrypt(str[I])..., 0 } { }
inline const char* decrypt()
{
for (size_t i = 0; i < sizeof...(I); ++i)
m_buffer[i] = decrypt(m_buffer[i]);
return const_cast<const char*>(m_buffer);
}
private:
// key 绝对不能为 0
constexpr char key(char key) const { return 1 + (key % 13); }
constexpr char __forceinline encrypt(char c) const { return c + key(K); }
constexpr char decrypt(char c) const { return c - key(K); }
volatile char m_buffer[sizeof...(I) + 1];
};
汇总使用:
template<int N>
struct MetaRandomChar
{
// 最大值 0x7F
static const char value = static_cast<char>(1 + MetaRandom<N, 0x7F - 1>::value);
};
#define DEF_OBFUSCATED(str) MetaString<MetaRandom<__COUNTER__, 3>::value, \
MetaRandomChar<__COUNTER__>::value, \
Make_Indexes<sizeof(str) - 1>::type>(str)
#define OBFUSCATED(str) (DEF_OBFUSCATED(str).decrypt())
int main() {
auto temp = DEF_OBFUSCATED("1234");
auto cstr = temp.decrypt();
return 0;
}
尾声
Debug 版本貌似字符串还存在,Release 版本就没有了。 只弄了 char 的情况,wchar 类似,不再累述。
- 字符串直接使用的情况:
const char* str = OBFUSCATED("Baby Hai's Secret");–- 拿到指针,指针对应的临时变量MetaString就释放了,非法用法。const std::string stdstr = OBFUSCATED("Baby Hai's Secret");–- stdstr 完成构造,对应的临时变量MetaString才释放,正确。
- 定义和使用分离:
auto metastr = DEF_OBFUSCATED("Baby Hai's Secret");const char* str = metastr.decrypt();
编译出来的二进制就反编译不到对应的字符串了,而且代码的可读性也保证了。
更多思考 :最底层应该是基于汇编的优化,当一个函数是确定的,参数也是确定的,直接在编译期就可以算出结果了。
xorstr.hpp
发现一个貌似更牛的版本,等有时间了,好好学习一下。
xorstr  A heavily vectorized c++17 compile time string encryption.
A heavily vectorized c++17 compile time string encryption.
用 Intel AVX 并行计算。<immintrin.h> 进行了汇编优化。AVX 指令集 ![]()
- Intel CPU 是否支持 AVX 不能只看 i3/i5/i7、奔腾、赛扬这些品牌名;通常 Sandy Bridge 及之后的很多 Core 处理器支持 AVX,但仍应以 CPUID 或系统 / 编译器检测结果为准。
- 如果是 AMD 的产品,则推土机架构以后的 FX、速龙系列、APU、锐龙系列都支持。
最简单的方法是用 CPU-z 检测一下,一目了然。
启用增强指令集 允许使用支持增强指令集的处理器上的指令,例如,IA-32 的 SSE、SSE2、AVX、AVX2 和 AVX-512 增强;x64 的 AVX、AVX2 和 AVX-512 增强。 当前只有在为 x86 体系结构生成程序时,/arch:SSE 和 /arch:SSE2 才可用。如果未指定任何选项,则编译器将使用支持 SSE2 的处理器上的指令。 可以通过 /arch:lA32 禁用对增强指令的使用。(/arch:SSE、/arch:SSE2、/arch:AVX、/arch:AVX2、/arch:AVX512、/arch:lA32)
quick example
int main() {
std::puts(XORSTR("an extra long hello_world"));
}
API
// This macro creates an encrypted xor_string string instance.
#define XORSTR_DEF(string) xor_string<...>{string}
// For convenience sake there is also a macro to instantly decrypt the string
#define XORSTR(string) XORSTR_DEF(string).decrypt()
struct xor_string<CharType, ...> {
using size_type = std::size_t;
using value_type = CharT;
using pointer = value_type*;
using const_pointer = const value_type*;
// Returns string size in characters, not including null terminator.
constexpr size_type size() const;
// Runs the encryption/decryption algorithm on the internal storage.
void crypt() noexcept;
// Returns const pointer to the storage, without doing any modifications to it.
const_pointer get() const;
// Returns non const pointer to the storage, without doing any modifications to it.
pointer get();
// Runs crypt() and returns the pointer to the internal storage.
pointer decrypt();
}
noteworthy things
- All keys are 64bit and generated during compile time.
- Data blocks go in increments of 16 bytes so some space may be wasted.
- The code has been crafted so that all the data would be embedded directly into code and not stored on .rdata and such.
- The entirety of string encryption and decryption will be inlined.
supported compilers and platforms
- Tested to be working on clang 5.0+, gcc 7.1+ and MSVC v141.
- If your CPU does not support AVX define JM_XORSTR_DISABLE_AVX_INTRINSICS to only use SSE.
- 在实际工程中, JM_XORSTR_DISABLE_AVX_INTRINSICS 我屏蔽掉了 AVX 指令集优化。
example assembly output
Output of gcc (trunk) from the quick example
生成的 AVX VMOVDQA 汇编指令集。
main:
movabs rax, -4762152789334367252
push rbp
mov rbp, rsp
and rsp, -32
sub rsp, 64
mov QWORD PTR [rsp], rax
mov rdi, rsp
movabs rax, -6534519754492314190
mov QWORD PTR [rsp+8], rax
movabs rax, -2862143164529545214
mov QWORD PTR [rsp+16], rax
movabs rax, -4140208776682645948
mov QWORD PTR [rsp+24], rax
vmovdqa ymm1, YMMWORD PTR [rsp]
movabs rax, -2550414817236710003
mov QWORD PTR [rsp+32], rax
movabs rax, -4595755740016602734
mov QWORD PTR [rsp+40], rax
movabs rax, -5461194525092864914
mov QWORD PTR [rsp+48], rax
movabs rax, -4140208776682645984
mov QWORD PTR [rsp+56], rax
vpxor ymm0, ymm1, YMMWORD PTR [rsp+32]
vmovdqa YMMWORD PTR [rsp], ymm0
vzeroupper
call puts
xor eax, eax
leave
ret
source code
/*
* Copyright 2017 - 2021 Justas Masiulis
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef JM_XORSTR_HPP
#define JM_XORSTR_HPP
#if defined(_M_ARM64) || defined(__aarch64__) || defined(_M_ARM) || defined(__arm__)
#include <arm_neon.h>
#elif defined(_M_X64) || defined(__amd64__) || defined(_M_IX86) || defined(__i386__)
#include <immintrin.h>
#else
#error Unsupported platform
#endif
#include <cstdint>
#include <cstddef>
#include <utility>
#include <type_traits>
#define XORSTR_DEF(str) ::jm::xor_string([]() { return str; }, \
std::integral_constant<std::size_t, sizeof(str) / sizeof(*str)>{}, \
std::make_index_sequence<::jm::detail::_buffer_size<sizeof(str)>()>{})
#define XORSTR(str) XORSTR_DEF(str).decrypt()
#ifdef _MSC_VER
#define XORSTR_FORCEINLINE __forceinline
#else
#define XORSTR_FORCEINLINE __attribute__((always_inline)) inline
#endif
namespace jm {
namespace detail {
template<std::size_t Size>
XORSTR_FORCEINLINE constexpr std::size_t _buffer_size()
{
return ((Size / 16) + (Size % 16 != 0)) * 2;
}
template<std::uint32_t Seed>
XORSTR_FORCEINLINE constexpr std::uint32_t key4() noexcept
{
std::uint32_t value = Seed;
for(char c : __TIME__)
value = static_cast<std::uint32_t>((value ^ c) * 16777619ull);
return value;
}
template<std::size_t S>
XORSTR_FORCEINLINE constexpr std::uint64_t key8()
{
constexpr auto first_part = key4<2166136261 + S>();
constexpr auto second_part = key4<first_part>();
return (static_cast<std::uint64_t>(first_part) << 32) | second_part;
}
// loads up to 8 characters of string into uint64 and xors it with the key
template<std::size_t N, class CharT>
XORSTR_FORCEINLINE constexpr std::uint64_t
load_xored_str8(std::uint64_t key, std::size_t idx, const CharT* str) noexcept
{
using cast_type = typename std::make_unsigned<CharT>::type;
constexpr auto value_size = sizeof(CharT);
constexpr auto idx_offset = 8 / value_size;
std::uint64_t value = key;
for(std::size_t i = 0; i < idx_offset && i + idx * idx_offset < N; ++i)
value ^=
(std::uint64_t{ static_cast<cast_type>(str[i + idx * idx_offset]) }
<< ((i % idx_offset) * 8 * value_size));
return value;
}
// forces compiler to use registers instead of stuffing constants in rdata
XORSTR_FORCEINLINE std::uint64_t load_from_reg(std::uint64_t value) noexcept
{
#if defined(__clang__) || defined(__GNUC__)
asm("" : "=r"(value) : "0"(value) :);
return value;
#else
volatile std::uint64_t reg = value;
return reg;
#endif
}
} // namespace detail
template<class CharT, std::size_t Size, class Keys, class Indices>
class xor_string;
template<class CharT, std::size_t Size, std::uint64_t... Keys, std::size_t... Indices>
class xor_string<CharT, Size, std::integer_sequence<std::uint64_t, Keys...>, std::index_sequence<Indices...>> {
#ifndef JM_XORSTR_DISABLE_AVX_INTRINSICS
constexpr static inline std::uint64_t alignment = ((Size > 16) ? 32 : 16);
#else
constexpr static inline std::uint64_t alignment = 16;
#endif
alignas(alignment) std::uint64_t _storage[sizeof...(Keys)];
public:
using value_type = CharT;
using size_type = std::size_t;
using pointer = CharT*;
using const_pointer = const CharT*;
template<class L>
XORSTR_FORCEINLINE xor_string(L l, std::integral_constant<std::size_t, Size>,
std::index_sequence<Indices...>) noexcept
: _storage{ ::jm::detail::load_from_reg(
(std::integral_constant<std::uint64_t, detail::load_xored_str8<Size>(Keys, Indices, l())>::value))... }
{}
XORSTR_FORCEINLINE constexpr size_type size() const noexcept
{
return Size - 1;
}
XORSTR_FORCEINLINE void crypt() noexcept
{
// everything is inlined by hand because a certain compiler with a certain linker is _very_ slow
#if defined(__clang__)
alignas(alignment)
std::uint64_t arr[]{ ::jm::detail::load_from_reg(Keys)... };
std::uint64_t* keys =
(std::uint64_t*)::jm::detail::load_from_reg((std::uint64_t)arr);
#else
alignas(alignment) std::uint64_t keys[]{ ::jm::detail::load_from_reg(Keys)... };
#endif
#if defined(_M_ARM64) || defined(__aarch64__) || defined(_M_ARM) || defined(__arm__)
#if defined(__clang__)
((Indices >= sizeof(_storage) / 16 ? static_cast<void>(0) : __builtin_neon_vst1q_v(
reinterpret_cast<uint64_t*>(_storage) + Indices * 2,
veorq_u64(__builtin_neon_vld1q_v(reinterpret_cast<const uint64_t*>(_storage) + Indices * 2, 51),
__builtin_neon_vld1q_v(reinterpret_cast<const uint64_t*>(keys) + Indices * 2, 51)),
51)), ...);
#else // GCC, MSVC
((Indices >= sizeof(_storage) / 16 ? static_cast<void>(0) : vst1q_u64(
reinterpret_cast<uint64_t*>(_storage) + Indices * 2,
veorq_u64(vld1q_u64(reinterpret_cast<const uint64_t*>(_storage) + Indices * 2),
vld1q_u64(reinterpret_cast<const uint64_t*>(keys) + Indices * 2)))), ...);
#endif
#elif !defined(JM_XORSTR_DISABLE_AVX_INTRINSICS)
((Indices >= sizeof(_storage) / 32 ? static_cast<void>(0) : _mm256_store_si256(
reinterpret_cast<__m256i*>(_storage) + Indices,
_mm256_xor_si256(
_mm256_load_si256(reinterpret_cast<const __m256i*>(_storage) + Indices),
_mm256_load_si256(reinterpret_cast<const __m256i*>(keys) + Indices)))), ...);
if constexpr(sizeof(_storage) % 32 != 0)
_mm_store_si128(
reinterpret_cast<__m128i*>(_storage + sizeof...(Keys) - 2),
_mm_xor_si128(_mm_load_si128(reinterpret_cast<const __m128i*>(_storage + sizeof...(Keys) - 2)),
_mm_load_si128(reinterpret_cast<const __m128i*>(keys + sizeof...(Keys) - 2))));
#else
((Indices >= sizeof(_storage) / 16 ? static_cast<void>(0) : _mm_store_si128(
reinterpret_cast<__m128i*>(_storage) + Indices,
_mm_xor_si128(_mm_load_si128(reinterpret_cast<const __m128i*>(_storage) + Indices),
_mm_load_si128(reinterpret_cast<const __m128i*>(keys) + Indices)))), ...);
#endif
}
XORSTR_FORCEINLINE const_pointer get() const noexcept
{
return reinterpret_cast<const_pointer>(_storage);
}
XORSTR_FORCEINLINE pointer get() noexcept
{
return reinterpret_cast<pointer>(_storage);
}
XORSTR_FORCEINLINE pointer decrypt() noexcept
{
// crypt() is inlined by hand because a certain compiler with a certain linker is _very_ slow
#if defined(__clang__)
alignas(alignment)
std::uint64_t arr[]{ ::jm::detail::load_from_reg(Keys)... };
std::uint64_t* keys =
(std::uint64_t*)::jm::detail::load_from_reg((std::uint64_t)arr);
#else
alignas(alignment) std::uint64_t keys[]{ ::jm::detail::load_from_reg(Keys)... };
#endif
#if defined(_M_ARM64) || defined(__aarch64__) || defined(_M_ARM) || defined(__arm__)
#if defined(__clang__)
((Indices >= sizeof(_storage) / 16 ? static_cast<void>(0) : __builtin_neon_vst1q_v(
reinterpret_cast<uint64_t*>(_storage) + Indices * 2,
veorq_u64(__builtin_neon_vld1q_v(reinterpret_cast<const uint64_t*>(_storage) + Indices * 2, 51),
__builtin_neon_vld1q_v(reinterpret_cast<const uint64_t*>(keys) + Indices * 2, 51)),
51)), ...);
#else // GCC, MSVC
((Indices >= sizeof(_storage) / 16 ? static_cast<void>(0) : vst1q_u64(
reinterpret_cast<uint64_t*>(_storage) + Indices * 2,
veorq_u64(vld1q_u64(reinterpret_cast<const uint64_t*>(_storage) + Indices * 2),
vld1q_u64(reinterpret_cast<const uint64_t*>(keys) + Indices * 2)))), ...);
#endif
#elif !defined(JM_XORSTR_DISABLE_AVX_INTRINSICS)
((Indices >= sizeof(_storage) / 32 ? static_cast<void>(0) : _mm256_store_si256(
reinterpret_cast<__m256i*>(_storage) + Indices,
_mm256_xor_si256(
_mm256_load_si256(reinterpret_cast<const __m256i*>(_storage) + Indices),
_mm256_load_si256(reinterpret_cast<const __m256i*>(keys) + Indices)))), ...);
if constexpr(sizeof(_storage) % 32 != 0)
_mm_store_si128(
reinterpret_cast<__m128i*>(_storage + sizeof...(Keys) - 2),
_mm_xor_si128(_mm_load_si128(reinterpret_cast<const __m128i*>(_storage + sizeof...(Keys) - 2)),
_mm_load_si128(reinterpret_cast<const __m128i*>(keys + sizeof...(Keys) - 2))));
#else
((Indices >= sizeof(_storage) / 16 ? static_cast<void>(0) : _mm_store_si128(
reinterpret_cast<__m128i*>(_storage) + Indices,
_mm_xor_si128(_mm_load_si128(reinterpret_cast<const __m128i*>(_storage) + Indices),
_mm_load_si128(reinterpret_cast<const __m128i*>(keys) + Indices)))), ...);
#endif
return (pointer)(_storage);
}
};
template<class L, std::size_t Size, std::size_t... Indices>
xor_string(L l, std::integral_constant<std::size_t, Size>, std::index_sequence<Indices...>) -> xor_string<
std::remove_const_t<std::remove_reference_t<decltype(l()[0])>>,
Size,
std::integer_sequence<std::uint64_t, detail::key8<Indices>()...>,
std::index_sequence<Indices...>>;
} // namespace jm
#endif // include guard
精简一下,便于阅读理解。
#ifndef JM_XORSTR_HPP
#define JM_XORSTR_HPP
#include <immintrin.h>
#include <cstdint>
#include <cstddef>
#include <utility>
#include <type_traits>
namespace jm {
namespace detail {
template <std::size_t Size>
__forceinline constexpr std::size_t _buffer_size() {
return ((Size / 16) + (Size % 16 != 0)) * 2;
}
template <std::uint32_t Seed>
__forceinline constexpr std::uint32_t key4() noexcept {
std::uint32_t value = Seed;
for (char c : __TIME__) { // FNVHash
// Rabin-Karp 算法中的素数
// FNV_prime 值为 2^24 + 2^8 + 0x93 = 16777619
value = static_cast<std::uint32_t>((value ^ c) * 16777619ull);
}
return value;
}
template <std::size_t S>
__forceinline constexpr std::uint64_t key8() {
// 32 位的 offset_basis 值为 2166136261=0x811c9dc5
constexpr auto first_part = key4<2166136261 + S>();
constexpr auto second_part = key4<first_part>();
return (static_cast<std::uint64_t>(first_part) << 32) | second_part;
}
// loads up to 8 characters of string into uint64 and xors it with the key
// 每次 64 位,64 位 的 算,速度优化。
template <std::size_t N, class CharT>
__forceinline constexpr std::uint64_t load_xored_str8(std::uint64_t key,
std::size_t idx, const CharT* str) noexcept {
using cast_type = typename std::make_unsigned<CharT>::type;
// char: value_size=1, idx_offset=8
// wchar: value_size=2, idx_offset=4
constexpr auto value_size = sizeof(CharT);
constexpr auto block_size = 8 / value_size; // 每次计算 64 位,就是 8 字节
std::uint64_t value = key;
for (std::size_t i = 0; i < block_size && idx * block_size + i < N; ++i) {
auto offset = i * 8 * value_size;
auto p = static_cast<cast_type>(str[idx * block_size + i]);
value ^= std::uint64_t{p} << offset;
}
return value;
}
// forces compiler to use registers instead of stuffing constants in rdata
// 强制使用 寄存器,避免常量在 pe 的 rdata 里面。
__forceinline std::uint64_t load_from_reg(std::uint64_t value) noexcept {
volatile std::uint64_t reg = value;
return reg;
}
}; // namespace detail
}; // namespace jm
namespace jm {
template <class CharT, std::size_t Size, class Keys, class Indices>
class xor_string;
template <class CharT, std::size_t Size, std::uint64_t... Keys, std::size_t... Indices>
// std::integer_sequence: a sequence 0, 1, 2, ..., N-1
class xor_string<CharT, Size,
std::integer_sequence<std::uint64_t, Keys...>,
std::index_sequence<Indices...>> {
constexpr static inline std::uint64_t alignment = ((Size > 16) ? 32 : 16);
alignas(alignment) std::uint64_t _storage[sizeof...(Keys)];
public:
using value_type = CharT;
using size_type = std::size_t;
using pointer = CharT*;
using const_pointer = const CharT*;
// std::integral_constant 包装特定类型的静态常量
// L l -- 是一个 lambda 函数。
template <class L>
__forceinline xor_string(L l,
std::integral_constant<std::size_t, Size>,
std::index_sequence<Indices...>) noexcept
: _storage{::jm::detail::load_from_reg(
(std::integral_constant<std::uint64_t,
detail::load_xored_str8<Size>(Keys, Indices, l())>::value))...} {
}
// 字符串长度。
__forceinline constexpr size_type size() const noexcept {
return Size - 1;
}
__forceinline void crypt() noexcept {
// everything is inlined by hand because a certain compiler with a certain linker is _very_ slow
alignas(alignment) std::uint64_t keys[]{::jm::detail::load_from_reg(Keys)...};
/**
* Intel AVX 并行计算。<immintrin.h>
* _mm256_load_si256 / _mm256_store_si256 -- Move Aligned Packed Integer Values
* **** VMOVDQA ymm1, m256
* **** VMOVDQA m256, ymm1
* Moves 256 bits of packed integer values from the source operand to the destination
*/
((Indices >= sizeof(_storage) / 32
? static_cast<void>(0)
: _mm256_store_si256(
reinterpret_cast<__m256i*>(_storage) + Indices,
_mm256_xor_si256(_mm256_load_si256(reinterpret_cast<const __m256i*>(_storage) + Indices),
_mm256_load_si256(reinterpret_cast<const __m256i*>(keys) + Indices)))),
...);
if constexpr (sizeof(_storage) % 32 != 0) { // 多出来的最后 16 位 单独处理一下。
_mm_store_si128(
reinterpret_cast<__m128i*>(_storage + sizeof...(Keys) - 2),
_mm_xor_si128(_mm_load_si128(reinterpret_cast<const __m128i*>(_storage + sizeof...(Keys) - 2)),
_mm_load_si128(reinterpret_cast<const __m128i*>(keys + sizeof...(Keys) - 2))));
}
}
__forceinline const_pointer get() const noexcept {
return reinterpret_cast<const_pointer>(_storage);
}
__forceinline pointer get() noexcept {
return reinterpret_cast<pointer>(_storage);
}
__forceinline pointer decrypt() noexcept {
// crypt() is inlined by hand because a certain compiler with a certain linker is _very_ slow
alignas(alignment) std::uint64_t keys[]{::jm::detail::load_from_reg(Keys)...};
// Intel AVX 并行计算。<immintrin.h>
((Indices >= sizeof(_storage) / 32
? static_cast<void>(0)
: _mm256_store_si256(
reinterpret_cast<__m256i*>(_storage) + Indices,
_mm256_xor_si256(_mm256_load_si256(reinterpret_cast<const __m256i*>(_storage) + Indices),
_mm256_load_si256(reinterpret_cast<const __m256i*>(keys) + Indices)))),
...);
if constexpr (sizeof(_storage) % 32 != 0) {
_mm_store_si128(
reinterpret_cast<__m128i*>(_storage + sizeof...(Keys) - 2),
_mm_xor_si128(_mm_load_si128(reinterpret_cast<const __m128i*>(_storage + sizeof...(Keys) - 2)),
_mm_load_si128(reinterpret_cast<const __m128i*>(keys + sizeof...(Keys) - 2))));
}
return (pointer)(_storage);
}
};
// 引用移除 : remove_reference
// 若类型 T 为引用类型,则提供成员 typedef type ,其为 T 所引用的类型。否则 type 为 T 。
// std::remove_const_t<std::remove_reference_t<decltype(l()[0])>> -- 取第一个字符的类型。
// std::integer_sequence<std::uint64_t, detail::key8<Indices>()...> -- xor key 序列。
// std::index_sequence<Indices...> -- 下标数组。
template <class L, std::size_t Size, std::size_t... Indices>
xor_string(L l, std::integral_constant<std::size_t, Size>, std::index_sequence<Indices...>)
-> xor_string<std::remove_const_t<std::remove_reference_t<decltype(l()[0])>>, \
Size, \
std::integer_sequence<std::uint64_t, detail::key8<Indices>()...>, \
std::index_sequence<Indices...>>;
}; // namespace jm
#define XORSTRDEF(str) ::jm::xor_string([]() { return str; }, \
std::integral_constant<std::size_t, sizeof(str) / sizeof(*str)>{}, \
std::make_index_sequence<::jm::detail::_buffer_size<sizeof(str)>()>{})
#define XORSTR(str) XORSTRDEF(str).decrypt()
#endif // include guard
decode
#include <iostream>
#include "../MetaString4.h"
void mainstr() {
auto temp = DEF_OBFUSCATED4("abc");
printf("%s", temp.decrypt());
}
void mainstrw() {
auto temp = DEF_OBFUSCATED4(L"abc");
wprintf(L"%s", temp.decrypt());
}
int main()
{
mainstr();
mainstrw();
return 0;
}
; Attributes: bp-based frame
; int __cdecl main()
_main proc near
var_48= dword ptr -48h
var_44= dword ptr -44h
var_40= xmmword ptr -40h
var_30= xmmword ptr -30h
var_20= xmmword ptr -20h
var_4= dword ptr -4
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 50h
mov eax, ___security_cookie
xor eax, esp
mov [esp+50h+var_4], eax
mov [esp+50h+var_48], 2F3191A4h
mov [esp+50h+var_44], 0E0971183h
mov eax, [esp+50h+var_48]
mov ecx, [esp+50h+var_44]
mov dword ptr [esp+50h+var_30], eax
mov dword ptr [esp+50h+var_30+4], ecx
mov [esp+50h+var_48], 0C9BF4616h
mov [esp+50h+var_44], 52292A6Ah
mov eax, [esp+50h+var_48]
mov ecx, [esp+50h+var_44]
mov dword ptr [esp+50h+var_30+8], eax
mov dword ptr [esp+50h+var_30+0Ch], ecx
mov [esp+50h+var_48], 2F52F3C5h
mov [esp+50h+var_44], 0E0971183h
mov eax, [esp+50h+var_48]
mov ecx, [esp+50h+var_44]
mov dword ptr [esp+50h+var_40], eax
mov [esp+50h+var_48], 0C9BF4616h
mov dword ptr [esp+50h+var_40+4], ecx
mov [esp+50h+var_44], 52292A6Ah
mov eax, [esp+50h+var_48]
mov ecx, [esp+50h+var_44]
mov dword ptr [esp+50h+var_40+8], eax
lea eax, [esp+50h+var_30]
mov dword ptr [esp+50h+var_40+0Ch], ecx
movaps xmm1, [esp+50h+var_40]
pxor xmm1, [esp+50h+var_30]
push eax
push offset _Format ; "%s"
movaps [esp+58h+var_30], xmm1
call _printf
mov [esp+58h+var_48], 2F30F3A4h
mov [esp+58h+var_44], 0E09711E0h
mov eax, [esp+58h+var_48]
mov ecx, [esp+58h+var_44]
mov dword ptr [esp+58h+var_20], eax
mov dword ptr [esp+58h+var_20+4], ecx
mov [esp+58h+var_48], 0C9BF4616h
mov [esp+58h+var_44], 52292A6Ah
mov eax, [esp+58h+var_48]
mov ecx, [esp+58h+var_44]
mov dword ptr [esp+58h+var_20+8], eax
mov dword ptr [esp+58h+var_20+0Ch], ecx
mov [esp+58h+var_48], 2F52F3C5h
mov [esp+58h+var_44], 0E0971183h
mov eax, [esp+58h+var_48]
mov ecx, [esp+58h+var_44]
mov dword ptr [esp+58h+var_40], eax
mov [esp+58h+var_48], 0C9BF4616h
mov dword ptr [esp+58h+var_40+4], ecx
mov [esp+58h+var_44], 52292A6Ah
mov eax, [esp+58h+var_48]
mov ecx, [esp+58h+var_44]
mov dword ptr [esp+58h+var_40+8], eax
lea eax, [esp+58h+var_20]
mov dword ptr [esp+58h+var_40+0Ch], ecx
movaps xmm1, [esp+58h+var_40]
pxor xmm1, [esp+58h+var_20]
push eax
push offset aS ; "%s"
movaps [esp+60h+var_20], xmm1
call _wprintf
mov ecx, [esp+60h+var_4]
add esp, 10h
xor ecx, esp ; cookie
xor eax, eax
call @__security_check_cookie@4 ; __security_check_cookie(x)
mov esp, ebp
pop ebp
retn
_main endp
mainstr();
- ESP,extended stack pointer
- EBP,extended base pointer
C7 44 24 08 62 DE 0D 0E mov dword ptr [esp+8],0E0DDE62h # C7 44 24 xx ?? ?? ?? ??
C7 44 24 0C DA 71 8F 70 mov dword ptr [esp+0Ch],708F71DAh # C7 44 24 yy ?? ?? ?? ?? // yy = xx + 4
8B 44 24 08 mov eax,dword ptr [esp+8] # 8B 44 24 xx
8B 4C 24 0C mov ecx,dword ptr [esp+0Ch] # 8B 4C 24 yy
89 44 24 20 mov dword ptr [esp+20h],eax # 89 44 24 aa // 首地址 [esp+20h]
89 4C 24 24 mov dword ptr [esp+24h],ecx # 89 4C 24 bb // bb = aa + 4 [esp+24h]
C7 44 24 08 68 E1 DB 44 mov dword ptr [esp+8],44DBE168h # C7 44 24 xx ?? ?? ?? ??
C7 44 24 0C 87 9A 82 9D mov dword ptr [esp+0Ch],9D829A87h # C7 44 24 yy ?? ?? ?? ?? // yy = xx + 4
8B 44 24 08 mov eax,dword ptr [esp+8] # 8B 44 24 xx
8B 4C 24 0C mov ecx,dword ptr [esp+0Ch] # 8B 4C 24 yy
89 44 24 28 mov dword ptr [esp+28h],eax # 89 44 24 aa // 首地址 [esp+28h]
89 4C 24 2C mov dword ptr [esp+2Ch],ecx # 89 4C 24 bb // bb = aa + 4 [esp+2Ch]
C7 44 24 08 03 BC 6E 0E mov dword ptr [esp+8],0E6EBC03h # C7 44 24 xx ?? ?? ?? ??
C7 44 24 0C DA 71 8F 70 mov dword ptr [esp+0Ch],708F71DAh # C7 44 24 yy ?? ?? ?? ?? // yy = xx + 4
8B 44 24 08 mov eax,dword ptr [esp+8] # 8B 44 24 xx
8B 4C 24 0C mov ecx,dword ptr [esp+0Ch] # 8B 4C 24 yy
89 44 24 10 mov dword ptr [esp+10h],eax # 89 44 24 aa // 首地址 [esp+10h]
C7 44 24 08 68 E1 DB 44 mov dword ptr [esp+8],44DBE168h # C7 44 24 bb // bb = aa + 4 [esp+8]
89 4C 24 14 mov dword ptr [esp+14h],ecx # 89 4C 24 xx // 首地址 [esp+14h]
C7 44 24 0C 87 9A 82 9D mov dword ptr [esp+0Ch],9D829A87h # C7 44 24 yy ?? ?? ?? ??
8B 44 24 08 mov eax,dword ptr [esp+8] # 8B 44 24 xx
8B 4C 24 0C mov ecx,dword ptr [esp+0Ch] # 8B 4C 24 yy
89 44 24 18 mov dword ptr [esp+18h],eax # 89 44 24 yy
8D 44 24 20 lea eax,[esp+20h] # 8D 44 24 ??
89 4C 24 1C mov dword ptr [esp+1Ch],ecx # 89 4C 24 ??
0F 28 4C 24 10 movaps xmm1,xmmword ptr [esp+10h] # 0F 28 4C 24 ??
66 0F EF 4C 24 20 pxor xmm1,xmmword ptr [esp+20h] # 66 0F EF 4C 24 ??
50 push eax
68 00 21 F9 00 push offset string "%s" (0F92100h)
0F 29 4C 24 28 movaps xmmword ptr [esp+28h],xmm1
E8 0D FF FF FF call printf (0F91050h)
mainstrw();
C7 44 24 10 62 BC 0C 0E mov dword ptr [esp+10h],0E0CBC62h
C7 44 24 14 B9 71 8F 70 mov dword ptr [esp+14h],708F71B9h
8B 44 24 10 mov eax,dword ptr [esp+10h]
8B 4C 24 14 mov ecx,dword ptr [esp+14h]
89 44 24 38 mov dword ptr [esp+38h],eax
89 4C 24 3C mov dword ptr [esp+3Ch],ecx
C7 44 24 10 68 E1 DB 44 mov dword ptr [esp+10h],44DBE168h
C7 44 24 14 87 9A 82 9D mov dword ptr [esp+14h],9D829A87h
8B 44 24 10 mov eax,dword ptr [esp+10h]
8B 4C 24 14 mov ecx,dword ptr [esp+14h]
89 44 24 40 mov dword ptr [esp+40h],eax
89 4C 24 44 mov dword ptr [esp+44h],ecx
C7 44 24 10 03 BC 6E 0E mov dword ptr [esp+10h],0E6EBC03h
C7 44 24 14 DA 71 8F 70 mov dword ptr [esp+14h],708F71DAh
8B 44 24 10 mov eax,dword ptr [esp+10h]
8B 4C 24 14 mov ecx,dword ptr [esp+14h]
89 44 24 18 mov dword ptr [esp+18h],eax
C7 44 24 10 68 E1 DB 44 mov dword ptr [esp+10h],44DBE168h
89 4C 24 1C mov dword ptr [esp+1Ch],ecx
C7 44 24 14 87 9A 82 9D mov dword ptr [esp+14h],9D829A87h
8B 44 24 10 mov eax,dword ptr [esp+10h]
8B 4C 24 14 mov ecx,dword ptr [esp+14h]
89 44 24 20 mov dword ptr [esp+20h],eax
8D 44 24 38 lea eax,[esp+38h]
89 4C 24 24 mov dword ptr [esp+24h],ecx
0F 28 4C 24 18 movaps xmm1,xmmword ptr [esp+18h]
66 0F EF 4C 24 38 pxor xmm1,xmmword ptr [esp+38h]
50 push eax
68 04 21 F9 00 push offset string L"%s" (0F92104h)
0F 29 4C 24 40 movaps xmmword ptr [esp+40h],xmm1
E8 2E FE FF FF call wprintf (0F91010h)
IDA F5
int __cdecl main()
{
__m128i v0; // ST20_16
__m128i v2; // [esp+20h] [ebp-30h]
__m128i v3; // [esp+30h] [ebp-20h]
v2.m128i_i64[0] = 0xD413D0267133D9Ei64;
v2.m128i_i64[1] = 0x624D270D286B3C6Ci64;
v0.m128i_i64[0] = 0xD415A6402705FFFi64;
v0.m128i_i64[1] = 0x624D270D286B3C6Ci64;
v2 = _mm_xor_si128(v0, v2);
printf("%s", &v2);
v3.m128i_i64[0] = 0xD245A0702125F9Ei64;
v3.m128i_i64[1] = 0x624D270D280C3C0Ai64;
v0.m128i_i64[0] = 0xD415A6402705FFFi64;
v0.m128i_i64[1] = 0x624D270D286B3C6Ci64;
v3 = _mm_xor_si128(v0, v3);
wprintf(L"%s", &v3);
return 0;
}
参考资料快照
 .
.