编程与调试 C++ -- 字符串快速检索
需要解决的问题
给定一批 字符串 特征关键字,再给一个 文件,检索这批特征在里面的出现情况。
比如,给定三个关键字:
[
{ "key": "Baidu" },
{ "key": "kingsoft" },
{ "key": "program" },
{ "key": "中文" }
]
再给定一个文件 metastr.exe ,分析字符在其的出现情况。
问题分析
- 字符存在不同的编码方式:"utf8", "gbk", "utf-16-le"
- 转换成二进制后,再进行二进制检索。
方案一(正则匹配)
这批关键字构建字符串:
[\x00-\xff]{8}(?:(?:Baidu)|(?:B a i d u )|(?:kingsoft)|(?:k i n g s o f t )|(?:program)|(?:p r o g r a m )|(?:ä¸æ)|(?:ÖÐÎÄ)|(?:\-Ne))[\x00-\xff]{8}
这个看起来乱码,但是可以准确跑出结果的,而且结果是正确的。
构建正则的时候要特殊处理特殊字符 \\|+[](){}^$*.?- 等。
然后一个 Python 正则搞定:
retv = []
pattern = re.compile(regex, flags)
while True:
rlt = pattern.search(fdata)
if not rlt: break
begin, end = rlt.span()
result = fdatasrc[begin:end]
retv.append(result)
也可以搞一个 C++ 版本:
// 用正则进行二进制匹配
std::regex* reg = new std::regex(regex);
std::string tempstr(str, datasize);
// match_any 若多于一个匹配可行,则任何匹配都是可接受的结果。
bool result = std::regex_search(tempstr, *reg, std::regex_constants::match_any);
因为纯二进制的字符串,中间可能存在 0 的情况,所以要 std::string(str, datasize) 。
匹配任意字节不要直接依赖正则 . :它默认不匹配换行,且不同正则 / 文本模式对字节数据的语义容易踩坑;二进制检索更稳妥的写法是 [\\x00-\\xff] 。
慢是慢点,但是程序正确,能用。
正则方案的小缺陷
假如关键字是:trie , abab ,目标字符串是:trieabababab 。
答案应该有四个:trie abababab,trie abab abab,trieab abab ab,trieabab abab 。
但是正则只能找出其中三个,trieab abab ab 应该是找不出来的。
下面的 AC 自动机 方案完全没有这个小问题。
多模匹配之 AC 自动机
Aho-Corasick automation,该算法在 1975 年产生于贝尔实验室,是著名的多模匹配算法。
AC 自动机算法分为 3 步:(1) 构造一棵 Trie 树,(2) 构造 Fail 指针,(3) 模式匹配过程。
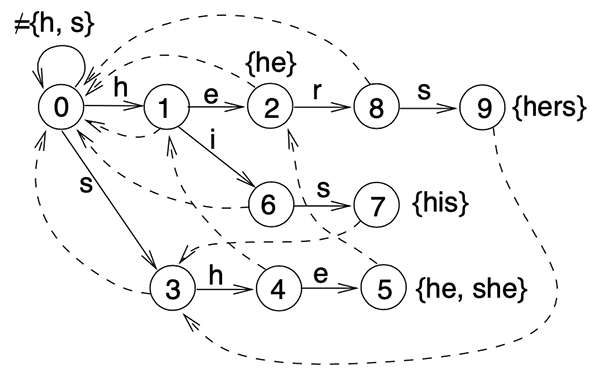
multi-pattern string search. Aho Corasick String Matching Algorithm

这个问题刚好是经典的 AC 自动机 算法。感觉算是基于 Trie 树的 二维 KMP 算法。
网上的代码很多,参考着自己也写了一个,纯二进制,相当于每个节点是 0x00-0xFF 。
Python 插件 pyahocorasick 是一个实现,但是不知道为什么非常慢,所以自己写了一个。
原型定义
typedef unsigned char BYTE;
typedef unsigned int UINT32;
typedef std::map<BYTE, struct Node*> CHILDREN;
typedef std::vector<int> WORDS;
typedef std::queue<Node*> NODEQUEUE;
#define CONTAINS(children, value) (children.find(value) != children.end())
struct Node {
Node* fail;
CHILDREN children;
int count; // 是否为该单词的最后一个节点
WORDS wordsizes; // 每个单词的长度
WORDS wordids; // 每个单词的 ID
Node() {
fail = NULL;
count = 0;
}
};
class Automaton {
public:
Automaton() {
m_root = new Node();
m_bPrintId = false;
m_nMaxWordSize = 0;
m_bDebug = false;
m_bIgnoreCase = false;
}
~Automaton() {
release(m_root);
}
public:
void insert(BYTE* data, int size, int id);
void build();
int query(BYTE* data, int size);
int query(BYTE* data, int offset, int size);
void output(BYTE* data, int offset, const WORDS& wordsizes, const WORDS& wordids);
void insert(const char* data, int id);
BOOL buildfromfile(const wchar_t* fpath);
void setPrintId(BOOL flag) {
m_bPrintId = flag;
}
void setIgnoreCase(BOOL ignore) {
m_bIgnoreCase = ignore;
}
void setDebug(BOOL flag) {
m_bDebug = flag;
}
int getMaxWordSize() {
return m_nMaxWordSize;
}
private:
void release(Node* node);
private:
Node* m_root;
BOOL m_bPrintId;
BOOL m_bIgnoreCase; // 对于二进制检索,可能不准确,因为各种编码的原因。
BOOL m_bDebug;
int m_nMaxWordSize;
Locker m_locker;
std::set<__int64> m_resultset;
};
我们需要支持是否忽略大小写,这里是不准确的。
比如字母 "A" 的 gbk 编码是 41 ,utf8 编码也是 41 ,但是 utf16le 编码是 41 00 。
而在 gbk 里面,包含 41 编码的 就有好多其它字符,比如 82 41 "侫 ", 85 41 "匒" 等等。
在 utf8 里面,只有字符:41 : "A"。
在 utf16le 里面,包含 41 编码的 "A" -> 41 00 ," 佁" -> 41 4f 等等。
在这个场景,多检出关系不大,一是数量不大很少,二是可以当作误报过滤掉。
数据插入 Trie 树
void Automaton::insert(BYTE* data, int size, int id) {
Node* p = m_root;
for (int i = 0; i < size; i++) {
BYTE key = data[i];
if (m_bIgnoreCase) {
if (key >= 'A' && key <= 'Z') {
key = key - 'A' + 'a';
}
}
if (!CONTAINS(p->children, key)) {
Node* temp = new Node();
p->children[key] = temp;
p = temp;
} else {
p = p->children[key];
}
}
p->count++;
p->wordsizes.push_back(size);
p->wordids.push_back(id);
m_nMaxWordSize = max(m_nMaxWordSize, size);
}
当忽略大小写检索的时候,构建树和检索的时候,都转换成相应的小写即可。
构建 fail 跳转
void Automaton::build() {
m_root->fail = NULL;
NODEQUEUE queue;
queue.push(m_root);
while (!queue.empty()) {
Node* temp = queue.front();
queue.pop();
CHILDREN::iterator iter = temp->children.begin();
for (; iter != temp->children.end(); iter++) {
BYTE key = iter->first;
Node* subnode = iter->second;
if (temp == m_root) {
subnode->fail = m_root;
} else {
Node* p = temp->fail;
while (p != NULL) {
if (CONTAINS(p->children, key)) {
subnode->fail = p->children[key];
break;
}
p = p->fail;
}
if (p == NULL) {
subnode->fail = m_root;
}
}
queue.push(subnode);
}
}
}
查询操作
int Automaton::query(BYTE* data, int offset, int size) {
Node* p = m_root;
int cnt = 0;
for (int i = offset; i < offset+size; i++) {
BYTE key = data[i];
if (m_bIgnoreCase) {
if (key >= 'A' && key <= 'Z') {
key = key - 'A' + 'a';
}
}
while (!CONTAINS(p->children, key) && p != m_root) {
p = p->fail;
}
if (CONTAINS(p->children, key)) {
p = p->children[key];
} else {
p = m_root;
}
Node* temp = p;
while (temp != m_root && temp->count != -1) {
cnt += temp->count;
#ifndef TOY_VERSION
temp->count = -1; // 如果已经统计进去了。
#else
if (temp->count) {
output(data, i, temp->wordsizes, temp->wordids);
}
#endif
temp = temp->fail;
}
}
return cnt;
}
结果打印
void Automaton::output(BYTE* data, int offset, //
const WORDS& wordsizes, const WORDS& wordids) //
{
AutoLocker temp(m_locker);
int size = wordsizes.size();
for (int i = 0; i < size; i++) {
int wordsizesize = wordsizes[i];
int start = offset - wordsizesize + 1;
__int64 hash = start;
hash = (hash << 32) + wordsizesize;
if (m_resultset.find(hash) != m_resultset.end()) {
continue;
}
m_resultset.insert(hash);
if (m_bPrintId) {
printf("%d %d %d\n", start, wordsizesize, wordids[i]);
} else {
char* buffer = new char[wordsizesize + 1];
memcpy(buffer, &data[start], wordsizesize);
buffer[wordsizesize] = 0;
printf("%d %d %s\n", start, wordsizesize, buffer);
delete[] buffer;
}
}
}
结果打印的时候 通过 AutoLocker 避免多线程问题,同时通过 hash set 去除重复。
多线程模式
树构建好了,查询的时候,对树是只读操作,并发是安全的。 把数据分成几段,每段跑一个线程查询。 段和段之间少许叠加,输出结果的时候简单去重即可。
struct ThreadData {
Automaton* automaton;
BYTE* data;
int offset;
int size;
};
DWORD WINAPI ThreadFun(LPVOID pm) {
ThreadData* data = (ThreadData*) pm;
data->automaton->query((BYTE*)data->data, data->offset, data->size);
return 0;
}
int testz(int argcz, wchar_t* argvz[]) {
if (!automaton.buildfromfile(keyfile)) {
return -1;
}
automaton.setPrintId(true);
long length = 0;
char* fdata = readfile(inputfile, length);
if (length < 1024 || threadcount == 1) {
automaton.query((BYTE*)fdata, length);
} else {
int piece = length / threadcount;
HANDLE* hThread = new HANDLE[threadcount];
ThreadData* hThreadData = new ThreadData[threadcount];
for(int i = 0; i < threadcount; i++) {
ThreadData& data = hThreadData[i];
data.automaton = &automaton;
data.data = (BYTE*)fdata;
data.offset = piece * i;
// 重叠部分,避免误差。
data.size = piece + automaton.getMaxWordSize() + 1;
if (data.offset + data.size > length) {
data.size = length - data.offset;
}
LPVOID lpParameter = &hThreadData[i];
hThread[i] = CreateThread(NULL, 0, ThreadFun, lpParameter, 0, NULL);
}
WaitForMultipleObjects(threadcount, hThread, TRUE, INFINITE);
for (int i = 0; i < threadcount; i++) {
CloseHandle(hThread[i]); // 关闭线程
}
delete[] hThread;
delete[] hThreadData;
}
delete[] fdata;
return 0;
}
还可以继续优化一下,把所有 output 放到一个单独的线程,负责 io 输出。
检索结果 json
{
"config": {
"rules": [
{
"key": "Baidu"
},
{
"key": "kingsoft"
},
{
"key": "program"
},
{
"key": "中文"
}
],
},
"report": [
{
"path": "test\\pesearch\\metastr.exe",
"target": {
"LÍ!This program cannot ": "UTF8:program:16 进制 4ccd21546869732070726f6772616d2063616e6e6f7420"
}
},
{
"path": "test\\pesearch\\test.txt",
"target": {
" BAIDU\r\nkingso": "UTF8:Baidu:16 进制 202020202020202042414944550d0a6b696e67736f",
" BAIDU\r\nkingsoft\r\nä¸æ": "UTF8:kingsoft:16 进制 2042414944550d0a6b696e67736f66740d0ae4b8ade69687",
"ngsoft\r\nä¸ææ ": "UTF8:中文:16 进制 6e67736f66740d0ae4b8ade69687e696872020202020"
}
}
]
}
看起来虽然乱码,但是都是 合法的 json,良民来的。
性能对比
一通浆糊下来,面对 300 MB 的二进制文件,和 几十个关键字 特征,从 正则方案 30 分钟 降低到了 2 分钟左右。棒 (๑•̀ㅂ•́)و✧
Windbg 中使用查找内存并设置访问断点
在 windbg 中通过 s 命令在内存中查找字符串或者关键字节码信息
0:005> s -u 00c00000 L1000000 "你好 20:15 2012/6/620:15 2012/6/6"
01960d28 4f60 597d 0020 0032 0030 003a 0031 0035 `O}Y .2.0.:.1.5.
查看内存 01960d28
01960d28 00 00 00 00 00 00 00 00 30 00 3a 00 31 00 35 00 20 00 ........0.:.1.5. .
01960d3a 32 00 30 00 31 00 32 00 2f 00 36 00 2f 00 36 00 32 00 2.0.1.2./.6./.6.2.
01960d4c 30 00 3a 00 31 00 35 00 20 00 32 00 30 00 31 00 32 00 0.:.1.5. .2.0.1.2.
....
01960d5e 2f 00 36 00 2f 00 36 00 00 00 00 00 00 00 00 00 00 00 /.6./.6...........
找到内容之后通过 ba 设置访问断点在任何函数访问该内存时将会中断
0:005> ba r4 01960d28
....
0:005> bl
0 du 0001 (0001) (@@masm( `ItemOperation.cpp:60+` ))
1 e 01960d28 r 4 0001 (0001) 0:****
2 e 771c3540 0001 (0001) 0:**** ntdll!DbgBreakPoint
如此在程序访问该地址时将会中断到调试器
0:005> g
Breakpoint 1 hit
eax=019607d0 ebx=00000023 ecx=00000003 edx=0000002c esi=019607d0 edi=01960cd0
eip=76d29c9c esp=000fefa4 ebp=000fefa8 iopl=0 nv up ei pl nz na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206
msvcrt!_VEC_memcpy+0x125:
76d29c9c 660f7f4760 movdqa xmmword ptr [edi+60h],xmm0 ds:0023:01960d30=003100300032002000350031003a0030
当然也可以根据自身需要查找相应的其他内容来实现设置相应的访问断点 note
跟踪
E:\wp\en_fqa.pdf
120.53.130.57 ip.dst==120.53.130.57
convert_req_id s -a 00400000 L009bf000 "convert_req_id"
0:002> s -a 00400000 L009bf000 "convert_req_id" 006c76e4 63 6f 6e 76 65 72 74 5f-72 65 71 5f 69 64 00 00 convert_req_id.. 006c7858 63 6f 6e 76 65 72 74 5f-72 65 71 5f 69 64 00 00 convert_req_id.. 006c7af8 63 6f 6e 76 65 72 74 5f-72 65 71 5f 69 64 00 00 convert_req_id..
ba r4 006c76e4 ba r4 006c7858 ba r4 006c7af8
Keywords Search
hdu 2222 - Keywords Search
算法 - 轻松掌握 ac 自动机  不是说你写不出来,而是你压根就没有机会写,新功能或者新项目,一定要围绕现有业务或者现金流展开或者拓展,逐步迭代,不能是空中楼阁。
不是说你写不出来,而是你压根就没有机会写,新功能或者新项目,一定要围绕现有业务或者现金流展开或者拓展,逐步迭代,不能是空中楼阁。
参考资料快照
- https://oi-wiki.org/string/ac-automaton/
- https://github.com/eecrazy/ACM/tree/master/%E5%AD%97%E7%AC%A6%E4%B8%B2
- https://forrestsu.github.io/posts/algorithm/ac-automation/
- https://www.cangkus.com/others/thecivilization/20001.html
- http://t.zoukankan.com/SkyMouse-p-2538745.html
- https://vjudge.net/problem/HDU-2222
- https://www.bilibili.com/video/BV1uJ411Y7Eg
 .
.