论文写作 -- 问题描述的五种范式总结
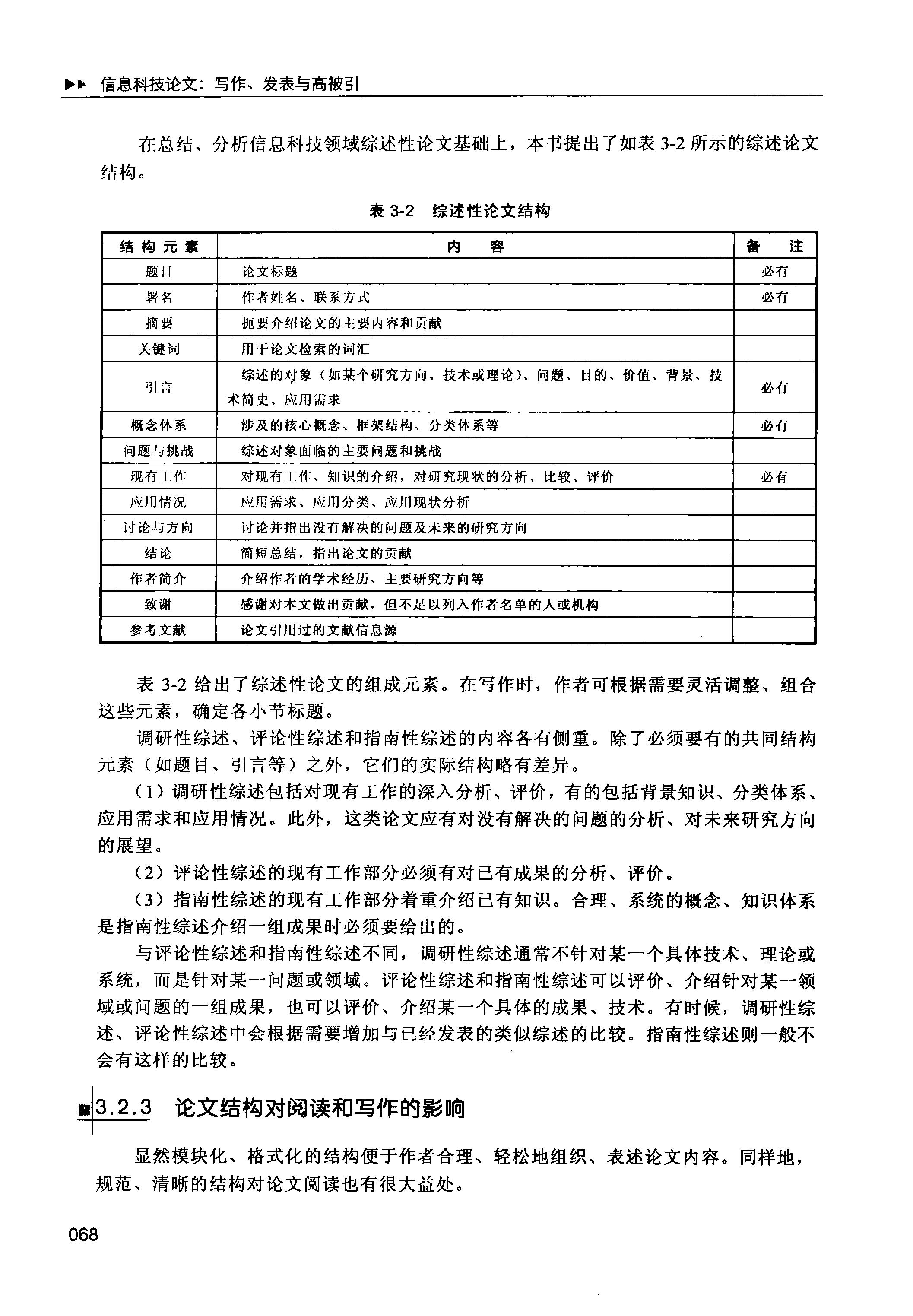
在总结、分析信息科技领域综述性论文基础上,本书提出了如表 3-2 所示的综述论文 结构。
表 3-2 综述性论文结构
| 结构元素 | 内 容 | 备 注 |
|---|---|---|
| 题目 | 论文标题 | 必有 |
| 署名 | 作者姓名、联系方式 | 必有 |
| 摘要 | 扼要介绍论文的主要内容和贡献 | |
| 关键词 | 用于论文检索的词汇 | |
| 引言 | 综述的可象(如某个研究方向、技术或理论)、问题、目的、价值、背景、技 术简史、应用需求 | 必有 |
| 概念体系 | 涉及的核心概念、框架结构、分类体系等 | 必有 |
| 问题与挑战 | 综述对象面临的主要问题和挑战 | |
| 现有工作 | 对现有工作、知识的介绍,对研究现状的分析、比较、评价 | 必有 |
| 应用情况 | 应用需求、应用分类、应用现状分析 | |
| 讨论与方向 | 讨论并指出没有解决的问题及未来的研究方向 | |
| 结论 | 简短总结,指出论文的贡献 | |
| 作者简介 | 介绍作者的学术经历、主要研究方向等 | |
| 致谢 | 感谢对本文做出贡献,但不足以列入作者名单的人或机构 | |
| 参考文献 | 论文引用过的文献信息源 |
表 3-2 给出了综述性论文的组成元素。在写作时,作者可根据需要灵活调整、组合 这些元素,确定各小节标题。
调研性综述、评论性综述和指南性综述的内容各有侧重。除了必须要有的共同结构 元素(如题目、引言等)之外,它们的实际结构略有差异。
- 调研性综述包括对现有工作的深入分析、评价,有的包括背景知识、分类体系、 应用需求和应用情况。此外,这类论文应有对没有解决的问题的分析、对未来研究方向 的展望。
- 评论性综述的现有工作部分必须有对已有成果的分析、评价。
- 指南性综述的现有工作部分着重介绍已有知识。合理、系统的概念、知识体系 是指南性综述介绍一组成果时必须要给出的。
与评论性综述和指南性综述不同,调研性综述通常不针对某一个具体技术、理论或 系统,而是针对某一问题或领域。评论性综述和指南性综述可以评价、介绍针对某一领 域或问题的一组成果,也可以评价、介绍某一个具体的成果、技术。有时候,调研性综 述、评论性综述中会根据需要增加与已经发表的类似综述的比较。指南性综述则一般不 会有这样的比较。
3.2.3 论文结构对阅读和写作的影响
显然模块化、格式化的结构便于作者合理、轻松地组织、表述论文内容。同样地, 规范、清晰的结构对论文阅读也有很大益处。
概览对比
| 研究类型 | 论文案例 | 问题定义特点 | 核心问题 |
|---|---|---|---|
| 实验性研究 | InstructGPT (2022) | 从现有技术缺陷出发 | 如何让语言模型从 "预测文本 "变成 "执行任务 "的智能体? |
| 原创性研究 | AlexNet (2012) | 从技术瓶颈突破出发 | 如何在大规模数据集上有效训练深度神经网络? |
| 集成性研究 | DenseNet (2017) | 从现有方法局限出发 | 如何让特征在层间高效传递和复用? |
| 基础研究 | GNN Power (2019) | 从理论空白出发 | GNN 的表达能力到底有多强,如何做到最强? |
| 应用研究 | COVID Track (2021) | 从实际需求出发 | 如何实现疫情的近实时监测和预测? |
实验性研究:InstructGPT
问题定义方式
从现有技术的明显缺陷出发 ,通过对比 "现状 vs 理想 "来凸显问题的紧迫性。
核心问题
如何让语言模型从 "预测文本 "变成 "听懂任务、执行任务 "的智能体?
问题描述结构
- 现状描述 :传统语言模型通过最大化下一个词的似然进行训练
- 问题暴露 :三大缺陷
- 不遵守指令 - 模型答非所问,不理解任务目标
- 输出有害内容 - 生成带偏见、冒犯性、虚假信息的回答
- 与人类价值不一致 - 追求 "高概率 "文本而非 "人类想要 "的文本
- 问题本质 :模型很聪明,但不听话、不懂人意
关键英文原文
核心问题描述 : "Large language models (LMs) can be 'prompted' to perform a range of natural language processing (NLP) tasks, given some examples of the task as input. However, these models often express unintended behaviors such as making up facts, generating biased or toxic text, or simply not following user instructions."
问题根源 : "This is because the language modeling objective used for many recent large LMs—predicting the next token on a webpage from the internet—is different from the objective 'follow the user's instructions helpfully and safely'. Thus, we say that the language modeling objective is misaligned."
技术实现细节
RLHF 三步训练流程详细数据 :
- SFT 阶段 :13k 高质量指令-回答对进行监督微调
- RM 阶段 :33k 提示的人工排序数据训练奖励模型
- PPO 阶段 :使用 Proximal Policy Optimization 算法优化
- 模型规模 :1.3B 参数的 InstructGPT 优于 175B 的 GPT-3
- 人类偏好率 :85±3% 的优胜率(相比 GPT-3)
核心技术创新 :
- 首次将人类反馈整合到大语言模型训练中
- 建立了从 "预测文本 "到 "执行任务 "的转换范式
- 奠定了 ChatGPT、GPT-4 的标准训练流程
实验设计特点 :
- 验证方法 :人类偏好排序评估
- 对照设计 :InstructGPT vs GPT-3 直接对比
- 评估维度 :有用性、真实性、无害性
原创性研究:AlexNet
问题定义方式
从技术瓶颈和计算限制出发 ,强调突破现有技术边界的必要性。
核心问题
如何在大规模数据集上有效训练深度神经网络,使其泛化性能足够好?
问题描述结构
- 技术背景 :2012 年前主流方法依靠手工特征 + 线性分类器
- 性能瓶颈 :传统方法在大规模数据集上表现极差
- 技术难点 :
- 网络太深容易过拟合
- 计算量巨大,CPU 无法承受
- 缺乏有效的正则化手段和优化技巧
关键英文原文
核心挑战 : "To learn about thousands of objects from millions of images, we need a model with a large learning capacity. However, the immense complexity of the object recognition task means that this problem cannot be specified even by a dataset as large as ImageNet, so our model should also have lots of prior knowledge to compensate for all the data we don't have."
计算瓶颈 : "Despite the attractive qualities of CNNs, and despite the relative efficiency of their local architecture, they have still been prohibitively expensive to apply in large scale to high-resolution images."
技术架构与性能
网络架构详细设计 :
- 层数结构 :5 个卷积层 + 3 个全连接层
- 参数规模 :约 60M 参数
- GPU 配置 :两块 NVIDIA GTX 580 GPU 并行训练
- 训练优化 :SGD + 动量优化器(momentum=0.9, learning rate=0.01)
性能突破数据 :
- 单模型 :Top-5 错误率 18.2%
- 集成模型 :7 个 CNN 集成后达到 15.3%
- 对比优势 :比传统方法(26.2%)低 10.9 个百分点
- 数据集规模 :ImageNet 120 万张训练图片,1000 个类别
技术创新要点 :
- 首次大规模使用 ReLU 激活函数(解决梯度饱和)
- 引入 Dropout 正则化技术(防止过拟合)
- 数据增强策略(随机裁剪、翻转)
- 局部响应归一化(LRN)
创新模式特征 :
- 突破性创新 :从零开始构建新范式
- 多项技术同时创新 :GPU + ReLU + Dropout + 数据增强
- 引发领域革命 :开启深度学习时代
集成性研究:DenseNet
问题定义方式
从现有先进方法的局限性出发 ,寻求进一步的改进和优化。
核心问题
如何构建一种网络,让特征能在层与层之间高效传递和复用,从而提升信息流动性与参数利用率?
问题描述结构
- 技术演进 :在 AlexNet 和 ResNet 之后,CNN 越来越深
- 新瓶颈 :深度网络出现的四大问题
- 梯度消失 / 信息传递困难
- 特征冗余严重
- 参数利用率低
- 特征复用不足
- 改进方向 :需要更高效的特征传递和复用机制
关键英文原文
深度网络的核心问题 : "As CNNs become increasingly deep, a new research problem emerges: as information about the input or gradient passes through many layers, it can vanish and 'wash out' by the time it reaches the end (or beginning) of the network."
DenseNet 的创新思路 : "Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output."
数学原理与技术细节
核心数学公式 :
传统 CNN:$x_l = H_l(x_{l-1})$
DenseNet:$x_l = H_l([x_0, x_1, x_2, \ldots, x_{l-1}])$
关键技术参数 :
- Growth Rate (k) :控制每层输出通道数
- ImageNet:k=32
- CIFAR:k=12
- 参数效率 :DenseNet-201 仅 20M 参数,性能匹敌 ResNet-101 的 40M+ 参数
- 网络组成 :Dense Block + Transition Layer(1×1 Conv + 2×2 Pooling)
技术创新要点 :
- Dense Connectivity :每层与所有前层直接连接,提高信息流动与梯度传播
- Feature Reuse :旧特征被重复使用,减少冗余计算
- Fewer Parameters :尽管连接很多,但因为通道数小,总参数反而更少
创新模式特征 :
- 渐进式改进 :基于现有技术(ResNet)优化
- 单一维度深度改进 :专注于特征传递和复用
- 提升效率和性能 :参数量减少约 2/3,性能相当
基础研究:GNN Power
问题定义方式
从理论理解的空白出发 ,强调基础理论研究的重要性。
核心问题
GNN 的表达能力(即区分不同图的能力)到底有多强,以及如何做到最强?
问题描述结构
- 技术现状 :已有多种 GNN 结构,性能表现不错
- 理论空白 :没人知道这些模型的表达能力到底有多强
- 具体问题 :
- 现有 GNN 能区分哪些图结构?
- GNN 的判别能力上限是什么?
- 能否设计判别能力最强的 GNN?
关键英文原文
理论理解的缺失 : "However, despite GNNs revolutionizing graph representation learning, there is limited understanding of their representational properties and limitations."
设计缺乏理论指导 : "The design of new GNNs is mostly based on empirical intuition, heuristics, and experimental trial-and-error. There is little theoretical understanding of the properties and limitations of GNNs, and formal analysis of GNNs' representational capacity is limited."
理论框架与数学证明
核心理论贡献 :
GIN 更新公式 : \(h_v^{(k)} = \text{MLP}^{(k)} \Big( (1+\epsilon^{(k)})\cdot h_v^{(k-1)} + \sum_{u\in N(v)} h_u^{(k-1)} \Big)\)
理论等价性证明 :
- GNN 表达能力 ≡ Weisfeiler-Lehman (WL) 测试判别能力
- 单射聚合函数是达到 WL 上限的必要条件
- GIN 是首个达到理论上限的实际可实现模型
设计原则 :
- Sum 聚合 :保证单射多重集函数特性
- MLP 更新 :提供足够的非线性表达能力
- 可学习 ε :平衡节点自身与邻居信息
创新模式特征 :
- 理论指导 :数学理论先行
- 构造最优解 :基于理论推导设计模型
- 指导后续发展 :为 GNN 架构设计提供理论基石
应用研究:COVID Track
问题定义方式
从实际应用需求出发 ,强调解决现实问题的迫切性。
核心问题
如何借助数字化的、近实时的人口流动 / 接触代理指标,来 "提前 "估计传播强度 Rt,并对未来疫情进行短期预测?
问题描述结构
- 实际挑战 :疫情传播监测面临的现实困难
- 监测滞后性:感染到报告约 9 天延迟
- 缺乏高频、近实时的接触 / 混合数据
- 应用需求 :需要更及时的传播监测方法
- 解决思路 :能否通过数字代理指标缩短滞后期
关键英文原文
实时追踪的挑战 : "Tracking the spread of COVID-19 infection in real time has been an elusive goal, given the necessary delay between infection and reporting. This delay consists of the incubation period (around 6 days), time between symptom onset and diagnosis (around 3 days), and the duration between confirmation and reporting (around half day). Therefore, there is around 9 days of delay even with instantaneous updating of case reports."
迫切需求 : "Taken together, it remains an urgent priority to develop new analytics that would allow truly real-time monitoring of transmissibility, thus the application of timely public health interventions in mitigation."
实证数据与应用效果
数据来源与规模 :
- 数字代理指标 :香港 Octopus 卡交易数据
- 年龄分组 :儿童、学生、成人、老年人
- 相关性验证 :交通类指标与 Rt 相关系数 0.62-0.80
- 时间延迟 :传统监测延迟约 9 天(感染→报告)
模型框架 :
- 年龄结构 SIR 模型 :动态接触矩阵参数化
- 反卷积方法 :报告时间→感染时间映射
- 验证方法 :回溯预测与实际趋势对比
实际应用效果 :
- Nowcast 准确性 :与经验 Rt 高度吻合
- 预测能力 :6 天短期预测表现良好
- 政策评估 :能及时检测干预措施效果
创新模式特征 :
- 实践驱动 :解决实际问题
- 验证可行性 :实地数据验证
- 推动应用落地 :为公共卫生决策提供支持
问题描述的五种范式总结
缺陷驱动型 (实验性研究)
- 特点 :从现有技术的明显缺陷出发
- 结构 :现状描述 → 问题暴露 → 问题本质
- 适用 :改进现有技术、验证新方法
瓶颈突破型 (原创性研究)
- 特点 :从技术瓶颈和计算限制出发
- 结构 :技术背景 → 性能瓶颈 → 技术难点
- 适用 :开创性技术、突破性创新
局限改进型 (集成性研究)
- 特点 :从现有先进方法的局限性出发
- 结构 :技术演进 → 新瓶颈 → 改进方向
- 适用 :技术优化、方法集成
理论空白型 (基础研究)
- 特点 :从理论理解的空白出发
- 结构 :技术现状 → 理论空白 → 具体问题
- 适用 :基础理论、理论分析
需求驱动型 (应用研究)
- 特点 :从实际应用需求出发
- 结构 :实际挑战 → 应用需求 → 解决思路
- 适用 :实际应用、问题解决
方法论对比分析
实验设计策略
| 研究类型 | 实验设计特点 | 验证方法 | 数据规模 |
|---|---|---|---|
| 实验性研究 | 对照实验 + 人类评估 | 人类偏好排序 | 13k SFT + 33k RM |
| 原创性研究 | 基准测试 + 消融实验 | 标准数据集评估 | 120 万图片,1000 类 |
| 集成性研究 | 参数效率对比 | 多数据集验证 | CIFAR + ImageNet |
| 基础研究 | 理论证明 + 实验验证 | 构造性证明 | 图分类基准 |
| 应用研究 | 实地验证 + 回溯测试 | 相关性分析 | 实时交易数据 |
写作启示
- 问题定义要与研究类型匹配 :不同类型的研究需要采用相应的问题描述范式
- 突出问题的重要性 :通过对比、数据、实例等方式强调问题的紧迫性
- 问题要具体可操作 :避免过于宽泛,要能指导具体的研究方向
- 英文原文的价值 :原文往往更精准地表达了问题的本质
- 结构化描述 :采用层次化的结构来逐步深入问题的核心
- 数据支撑论证 :用具体的数字和实验结果增强说服力
- 技术细节平衡 :既要有理论深度,又要保持可读性
- 创新点突出 :明确标识技术贡献和突破点